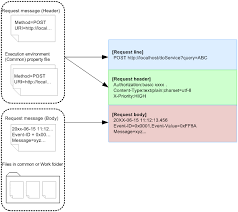
How Http Headers Work
HTTP headers – MDN Web Docs
HTTP headers let the client and the server pass additional information with an HTTP request or response. An HTTP header consists of its case-insensitive name followed by a colon (:), then by its value. Whitespace before the value is ignored.
Custom proprietary headers have historically been used with an X- prefix, but this convention was deprecated in June 2012 because of the inconveniences it caused when nonstandard fields became standard in RFC 6648; others are listed in an IANA registry, whose original content was defined in RFC 4229. IANA also maintains a registry of proposed new HTTP headers.
Headers can be grouped according to their contexts:
Request headers contain more information about the resource to be fetched, or about the client requesting the resource.
Response headers hold additional information about the response, like its location or about the server providing it.
Representation headers contain information about the body of the resource, like its MIME type, or encoding/compression applied.
Payload headers contain representation-independent information about payload data, including content length and the encoding used for transport.
Headers can also be grouped according to how proxies handle them:
Connection
Keep-Alive
Proxy-Authenticate
Proxy-Authorization
TE
Trailer
Transfer-Encoding
Upgrade (see also Protocol upgrade mechanism).
End-to-end headers
These headers must be transmitted to the final recipient of the message: the server for a request, or the client for a response. Intermediate proxies must retransmit these headers unmodified and caches must store them.
Hop-by-hop headers
These headers are meaningful only for a single transport-level connection, and must not be retransmitted by proxies or cached. Note that only hop-by-hop headers may be set using the Connection header.
Authentication
WWW-Authenticate
Defines the authentication method that should be used to access a resource.
Authorization
Contains the credentials to authenticate a user-agent with a server.
Defines the authentication method that should be used to access a resource behind a proxy server.
Contains the credentials to authenticate a user agent with a proxy server.
Caching
Age
The time, in seconds, that the object has been in a proxy cache.
Cache-Control
Directives for caching mechanisms in both requests and responses.
Clear-Site-Data
Clears browsing data (e. g. cookies, storage, cache) associated with the requesting website.
Expires
The date/time after which the response is considered stale.
Pragma
Implementation-specific header that may have various effects anywhere along the request-response chain. Used for backwards compatibility with HTTP/1. 0 caches where the Cache-Control header is not yet present.
Warning
General warning information about possible problems.
Client hintsHTTP Client hints are a set of request headers that provide useful information about the client such as device type and network conditions, and allow servers to optimize what is served for those conditions.
Servers proactively requests the client hint headers they are interested in from the client using Accept-CH. The client may then choose to include the requested headers in subsequent requests.
Accept-CH
Servers can advertise support for Client Hints using the Accept-CH header field or an equivalent HTML element with -equiv attribute.
Accept-CH-Lifetime
Servers can ask the client to remember the set of Client Hints that the server supports for a specified period of time, to enable delivery of Client Hints on subsequent requests to the server’s origin.
The different categories of client hints are listed client hints
Content-DPR
Response header used to confirm the image device to pixel ratio in requests where the DPR client hint was used to select an image resource.
Device-Memory
Approximate amount of available client RAM memory. This is part of the Device Memory API.
DPR
Client device pixel ratio (DPR), which is the number of physical device pixels corresponding to every CSS pixel.
Viewport-Width
A number that indicates the layout viewport width in CSS pixels. The provided pixel value is a number rounded to the smallest following integer (i. e. ceiling value).
Width
The Width request header field is a number that indicates the desired resource width in physical pixels (i. intrinsic size of an image).
Network client hintsNetwork client hints allow a server to choose what information is sent based on the user choice and network bandwidth and latency.
Downlink
Approximate bandwidth of the client’s connection to the server, in Mbps. This is part of the Network Information API.
ECT
The effective connection type (“network profile”) that best matches the connection’s latency and bandwidth. This is part of the Network Information API.
RTT
Application layer round trip time (RTT) in miliseconds, which includes the server processing time. This is part of the Network Information API.
Save-Data
A boolean that indicates the user agent’s preference for reduced data usage.
Conditionals
Last-Modified
The last modification date of the resource, used to compare several versions of the same resource. It is less accurate than ETag, but easier to calculate in some environments. Conditional requests using If-Modified-Since and If-Unmodified-Since use this value to change the behavior of the request.
ETag
A unique string identifying the version of the resource. Conditional requests using If-Match and If-None-Match use this value to change the behavior of the request.
If-Match
Makes the request conditional, and applies the method only if the stored resource matches one of the given ETags.
If-None-Match
Makes the request conditional, and applies the method only if the stored resource doesn’t match any of the given ETags. This is used to update caches (for safe requests), or to prevent uploading a new resource when one already exists.
If-Modified-Since
Makes the request conditional, and expects the resource to be transmitted only if it has been modified after the given date. This is used to transmit data only when the cache is out of date.
If-Unmodified-Since
Makes the request conditional, and expects the resource to be transmitted only if it has not been modified after the given date. This ensures the coherence of a new fragment of a specific range with previous ones, or to implement an optimistic concurrency control system when modifying existing documents.
Vary
Determines how to match request headers to decide whether a cached response can be used rather than requesting a fresh one from the origin server.
Connection management
Controls whether the network connection stays open after the current transaction finishes.
Controls how long a persistent connection should stay open.
Content negotiationContent negotiation headers.
Accept
Informs the server about the types of data that can be sent back.
Accept-Encoding
The encoding algorithm, usually a compression algorithm, that can be used on the resource sent back.
Accept-Language
Informs the server about the human language the server is expected to send back. This is a hint and is not necessarily under the full control of the user: the server should always pay attention not to override an explicit user choice (like selecting a language from a dropdown).
Controls
Expect
Indicates expectations that need to be fulfilled by the server to properly handle the request.
Max-Forwards
TBD
CookiesCORSDownloads
Content-Disposition
Indicates if the resource transmitted should be displayed inline (default behavior without the header), or if it should be handled like a download and the browser should present a “Save As” dialog.
Message body information
Content-Length
The size of the resource, in decimal number of bytes.
Content-Type
Indicates the media type of the resource.
Content-Encoding
Used to specify the compression algorithm.
Content-Language
Describes the human language(s) intended for the audience, so that it allows a user to differentiate according to the users’ own preferred language.
Content-Location
Indicates an alternate location for the returned data.
Proxies
Forwarded
Contains information from the client-facing side of proxy servers that is altered or lost when a proxy is involved in the path of the request.
X-Forwarded-For
Identifies the originating IP addresses of a client connecting to a web server through an HTTP proxy or a load balancer.
X-Forwarded-Host
Identifies the original host requested that a client used to connect to your proxy or load balancer.
X-Forwarded-Proto
Identifies the protocol (HTTP or HTTPS) that a client used to connect to your proxy or load balancer.
Via
Added by proxies, both forward and reverse proxies, and can appear in the request headers and the response headers.
Redirects
Location
Indicates the URL to redirect a page to.
Request context
From
Contains an Internet email address for a human user who controls the requesting user agent.
Host
Specifies the domain name of the server (for virtual hosting), and (optionally) the TCP port number on which the server is listening.
Referer
The address of the previous web page from which a link to the currently requested page was followed.
Referrer-Policy
Governs which referrer information sent in the Referer header should be included with requests made.
User-Agent
Contains a characteristic string that allows the network protocol peers to identify the application type, operating system, software vendor or software version of the requesting software user agent. See also the Firefox user agent string reference.
Response context
Allow
Lists the set of HTTP request methods supported by a resource.
Server
Contains information about the software used by the origin server to handle the request.
Range requests
Accept-Ranges
Indicates if the server supports range requests, and if so in which unit the range can be expressed.
Range
Indicates the part of a document that the server should return.
If-Range
Creates a conditional range request that is only fulfilled if the given etag or date matches the remote resource. Used to prevent downloading two ranges from incompatible version of the resource.
Content-Range
Indicates where in a full body message a partial message belongs.
Security
Cross-Origin-Embedder-Policy (COEP)
Allows a server to declare an embedder policy for a given document.
Cross-Origin-Opener-Policy (COOP)
Prevents other domains from opening/controlling a window.
Cross-Origin-Resource-Policy (CORP)
Prevents other domains from reading the response of the resources to which this header is applied.
Content-Security-Policy (CSP)
Controls resources the user agent is allowed to load for a given page.
Content-Security-Policy-Report-Only
Allows web developers to experiment with policies by monitoring, but not enforcing, their effects. These violation reports consist of JSON documents sent via an HTTP POST request to the specified URI.
Expect-CT
Allows sites to opt in to reporting and/or enforcement of Certificate Transparency requirements, which prevents the use of misissued certificates for that site from going unnoticed. When a site enables the Expect-CT header, they are requesting that Chrome check that any certificate for that site appears in public CT logs.
Feature-Policy
Provides a mechanism to allow and deny the use of browser features in its own frame, and in iframes that it embeds.
Origin-Isolation
Provides a mechanism to allow web applications to isolate their origins.
Strict-Transport-Security (HSTS)
Force communication using HTTPS instead of HTTP.
Upgrade-Insecure-Requests
Sends a signal to the server expressing the client’s preference for an encrypted and authenticated response, and that it can successfully handle the upgrade-insecure-requests directive.
X-Content-Type-Options
Disables MIME sniffing and forces browser to use the type given in Content-Type.
X-Download-Options
The X-Download-Options HTTP header indicates that the browser (Internet Explorer) should not display the option to “Open” a file that has been downloaded from an application, to prevent phishing attacks as the file otherwise would gain access to execute in the context of the application. (Note: related MS Edge bug).
X-Frame-Options (XFO)
Indicates whether a browser should be allowed to render a page in a ,