Website Crawling Tools
Top 20 web crawler tools to scrape the websites – Big Data …
Web crawling (also known as web scraping) is a process in which a program or automated script browses the World Wide Web in a methodical, automated manner and targets at fetching new or updated data from any websites and store the data for easy access. Web crawler tools are very popular these days as they have simplified and automated the entire crawling process and made the data crawling easy and accessible to everyone. In this post, we will look at the top 20 popular web crawlers around the web. 1. Cyotek WebCopyWebCopy is a free website crawler that allows you to copy partial or full websites locally into your hard disk for offline will scan the specified website before downloading the website content onto your hard disk and auto-remap the links to resources like images and other web pages in the site to match its local path, excluding a section of the website. Additional options are also available such as downloading a URL to include in the copy, but not crawling are many settings you can make to configure how your website will be crawled, in addition to rules and forms mentioned above, you can also configure domain aliases, user agent strings, default documents and ever, WebCopy does not include a virtual DOM or any form of JavaScript parsing. If a website makes heavy use of JavaScript to operate, it is unlikely WebCopy will be able to make a true copy if it is unable to discover all the website due to JavaScript being used to dynamically generate links. 2. HTTrackAs a website crawler freeware, HTTrack provides functions well suited for downloading an entire website from the Internet to your PC. It has provided versions available for Windows, Linux, Sun Solaris, and other Unix systems. It can mirror one site, or more than one site together (with shared links). You can decide the number of connections to opened concurrently while downloading web pages under “Set options”. You can get the photos, files, HTML code from the entire directories, update current mirrored website and resume interrupted, Proxy support is available with HTTTrack to maximize speed, with optional Track Works as a command-line program, or through a shell for both private (capture) or professional (on-line web mirror) use. With that saying, HTTrack should be preferred and used more by people with advanced programming skills. 3. OctoparseOctoparse is a free and powerful website crawler used for extracting almost all kind of data you need from the website. You can use Octoparse to rip a website with its extensive functionalities and capabilities. There are two kinds of learning mode – Wizard Mode and Advanced Mode – for non-programmers to quickly get used to Octoparse. After downloading the freeware, its point-and-click UI allows you to grab all the text from the website and thus you can download almost all the website content and save it as a structured format like EXCEL, TXT, HTML or your advanced, it has provided Scheduled Cloud Extraction which enables you to refresh the website and get the latest information from the you could extract many tough websites with difficult data block layout using its built-in Regex tool, and locate web elements precisely using the XPath configuration tool. You will not be bothered by IP blocking anymore since Octoparse offers IP Proxy Servers that will automate IP’s leaving without being detected by aggressive conclude, Octoparse should be able to satisfy users’ most crawling needs, both basic or high-end, without any coding skills. 4. GetleftGetleft is a free and easy-to-use website grabber that can be used to rip a website. It downloads an entire website with its easy-to-use interface and multiple options. After you launch the Getleft, you can enter a URL and choose the files that should be downloaded before begin downloading the website. While it goes, it changes the original pages, all the links get changed to relative links, for local browsing. Additionally, it offers multilingual support, at present Getleft supports 14 languages. However, it only provides limited Ftp supports, it will download the files but not recursively. Overall, Getleft should satisfy users’ basic crawling needs without more complex tactical skills. 5. ScraperThe scraper is a Chrome extension with limited data extraction features but it’s helpful for making online research, and exporting data to Google Spreadsheets. This tool is intended for beginners as well as experts who can easily copy data to the clipboard or store to the spreadsheets using OAuth. The scraper is a free web crawler tool, which works right in your browser and auto-generates smaller XPaths for defining URLs to crawl. It may not offer all-inclusive crawling services, but novices also needn’t tackle messy configurations. 6. OutWit HubOutWit Hub is a Firefox add-on with dozens of data extraction features to simplify your web searches. This web crawler tool can browse through pages and store the extracted information in a proper Hub offers a single interface for scraping tiny or huge amounts of data per needs. OutWit Hub lets you scrape any web page from the browser itself and even create automatic agents to extract data and format it per is one of the simplest web scraping tools, which is free to use and offers you the convenience to extract web data without writing a single line of code. 7. ParseHubParsehub is a great web crawler that supports collecting data from websites that use AJAX technologies, JavaScript, cookies etc. Its machine learning technology can read, analyze and then transform web documents into relevant desktop application of Parsehub supports systems such as Windows, Mac OS X and Linux, or you can use the web app that is built within the a freeware, you can set up no more than five public projects in Parsehub. The paid subscription plans allow you to create at least 20 private projects for scraping websites. 8. Visual ScraperVisualScraper is another great free and non-coding web scraper with a simple point-and-click interface and could be used to collect data from the web. You can get real-time data from several web pages and export the extracted data as CSV, XML, JSON or SQL files. Besides the SaaS, VisualScraper offers web scraping service such as data delivery services and creating software extractors Scraper enables users to schedule their projects to be run on a specific time or repeat the sequence every minute, days, week, month, year. Users could use it to extract news, updates, forum frequently. 9. ScrapinghubScrapinghub is a cloud-based data extraction tool that helps thousands of developers to fetch valuable data. Its open source visual scraping tool, allows users to scrape websites without any programming rapinghub uses Crawlera, a smart proxy rotator that supports bypassing bot counter-measures to crawl huge or bot-protected sites easily. It enables users to crawl from multiple IPs and locations without the pain of proxy management through a simple HTTP rapinghub converts the entire web page into organized content. Its team of experts is available for help in case its crawl builder can’t work your requirements. 10. a browser-based web crawler, allows you to scrape data based on your browser from any website and provide three types of the robot for you to create a scraping task – Extractor, Crawler, and Pipes. The freeware provides anonymous web proxy servers for your web scraping and your extracted data will be hosted on ’s servers for two weeks before the data is archived, or you can directly export the extracted data to JSON or CSV files. It offers paid services to meet your needs for getting real-time data. 11. enables users to get real-time data from crawling online sources from all over the world into various, clean formats. This web crawler enables you to crawl data and further extract keywords in many different languages using multiple filters covering a wide array of you can save the scraped data in XML, JSON and RSS formats. And users can access the history data from its Archive. Plus, supports at most 80 languages with its crawling data results. And users can easily index and search the structured data crawled by, could satisfy users’ elementary crawling requirements. 12. Import. ioUsers can form their own datasets by simply importing the data from a web page and exporting the data to can easily scrape thousands of web pages in minutes without writing a single line of code and build 1000+ APIs based on your requirements. Public APIs has provided powerful and flexible capabilities to control programmatically and gain automated access to the data, has made crawling easier by integrating web data into your own app or website with just a few better serve users’ crawling requirements, it also offers a free app for Windows, Mac OS X and Linux to build data extractors and crawlers, download data and sync with the online account. Plus, users can schedule crawling tasks weekly, daily or hourly. 13. 80legs80legs is a powerful web crawling tool that can be configured based on customized requirements. It supports fetching huge amounts of data along with the option to download the extracted data instantly. 80legs provides high-performance web crawling that works rapidly and fetches required data in mere seconds14. Spinn3rSpinn3r allows you to fetch entire data from blogs, news & social media sites and RSS & ATOM feed. Spinn3r is distributed with a firehouse API that manages 95% of the indexing work. It offers advanced spam protection, which removes spam and inappropriate language uses, thus improving data safety. Spinn3r indexes content like Google and save the extracted data in JSON files. The web scraper constantly scans the web and finds updates from multiple sources to get you real-time publications. Its admin console lets you control crawls and full-text search allows making complex queries on raw data. 15. Content GrabberContent Graber is a web crawling software targeted at enterprises. It allows you to create a stand-alone web crawling agents. It can extract content from almost any website and save it as structured data in a format of your choice, including Excel reports, XML, CSV, and most is more suitable for people with advanced programming skills, since it offers many powerful scripting editing, debugging interfaces for people in need. Users can use C# or to debug or write the script to control the crawling programming. For example, Content Grabber can integrate with Visual Studio 2013 for the most powerful script editing, debugging and unit test for an advanced and tactful customized crawler based on users’ particular needs. 16. Helium ScraperHelium Scraper is a visual web data crawling software that works well when the association between elements is small. It’s non-coding, non-configuration. And users can get access to the online templates based for various crawling needs. Basically, it could satisfy users’ crawling needs within an elementary level. 17. UiPathUiPath is a robotic process automation software for free web scraping. It automates web and desktop data crawling out of most third-party Apps. You can install the robotic process automation software if you run a Windows system. Uipath can extract tabular and pattern-based data across multiple web has provided the built-in tools for further crawling. This method is very effective when dealing with complex UIs. The Screen Scraping Tool can handle both individual text elements, groups of text and blocks of text, such as data extraction in table, no programming is needed to create intelligent web agents, but the hacker inside you will have complete control over the data. 18. Scrape. is a web scraping software for humans. It’s a cloud-based web data extraction tool. It’s designed towards those with advanced programming skills, since it has offered both public and private packages to discover, reuse, update, and share code with millions of developers worldwide. Its powerful integration will help you build a customized crawler based on your needs. 19. WebHarvyWebHarvy is a point-and-click web scraping software. It’s designed for non-programmers. WebHarvy can automatically scrape Text, Images, URLs & Emails from websites, and save the scraped content in various formats. It also provides built-in scheduler and proxy support which enables anonymously crawling and prevents the web scraping software from being blocked by web servers, you have the option to access target websites via proxy servers or can save the data extracted from web pages in a variety of formats. The current version of WebHarvy Web Scraper allows you to export the scraped data as an XML, CSV, JSON or TSV file. The user can also export the scraped data to an SQL database. 20. ConnotateConnotate is an automated web crawler designed for Enterprise-scale web content extraction which needs an enterprise-scale solution. Business users can easily create extraction agents in as little as minutes – without any programming. The user can easily create extraction agents simply by can automatically extract over 95% of sites without programming, including complex JavaScript-based dynamic site technologies, such as Ajax. And Connotate supports any language for data crawling from most ditionally, Connotate also offers the function to integrate webpage and database content, including content from SQL databases and MongoDB for database added to the list:21. Netpeak SpiderNetpeak Spider is a desktop tool for day-to-day SEO audit, quick search for issues, systematic analysis, and website program specializes in the analysis of large websites (we’re talking about millions of pages) with optimal use of RAM. You can simply import the data from web crawling and export the data to tpeak Spider allows you to scrape custom search of source code/text according to the 4 types of search: ‘Contains’, ‘RegExp’, ‘CSS Selector’, or ‘XPath’. A tool is useful for scraping for emails, names, etc.

60 Innovative Website Crawlers for Content Monitoring
In the digital age, almost everyone has an online presence. Most people will look online before stepping foot in a store because everything is available online—even if it’s just information on where to get the best products. We even look up cinema times online!
As such, staying ahead of the competition regarding visibility is no longer merely a matter of having a good marketing strategy. Newspaper and magazine articles, television and radio advertising, and even billboards (for those who can afford them) are no longer enough, even though they’re still arguably necessary.
Now, you also have to ensure that your site is better than your competitors’, from layout to content, and beyond. If you don’t, you’ll slip away into obscurity, like a well-kept secret among the locals—which doesn’t bode well for any business.
This notion is where search engine optimization (SEO) comes in. There is a host of SEO tools and tricks available to help put you ahead and increase your search engine page ranking—your online visibility. These range from your use of keywords, backlinks, and imagery, to your layout and categorization (usability and customer experience). One of these tools is the website crawler.
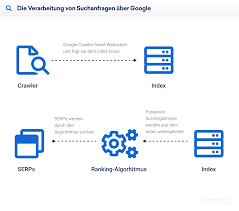
A website crawler is a software program used to scan sites, reading the content (and other information) so as to generate entries for the search engine index. All search engines use website crawlers (also known as a spider or bot). They typically work on submissions made by site owners and “crawl” new or recently modified sites and pages, to update the search engine index.
The crawler earned its moniker based on the way it works: by crawling through each page one at a time, following internal links until the entire site has been read, as well as following backlinks to determine the full scope of a site’s content. Crawlers can also be set to read the entire site or only specific pages that are then selectively crawled and indexed. By doing so, the website crawler can update the search engine index on a regular basis.
Website crawlers don’t have free reign, however. The Standard for Robot Exclusion (SRE) dictates the so-called “rules of politeness” for crawlers. Because of these specifications, a crawler will source information from the respective server to discover which files it may and may not read, and which files it must exclude from its submission to the search engine index. Crawlers that abide by the SRE are also unable to bypass firewalls, a further implementation designed to protect site owner’s’ privacy rights.
Lastly, the SRE also requires that website crawlers use a specialized algorithm. This algorithm allows the crawler to create search strings of operators and keywords, in order built onto the database (search engine index) of websites and pages for future search results. The algorithm also stipulates that the crawler waits between successive server requests, to prevent it from negatively impact the site’s response time for real (human) users visiting the site.
What Are the Benefits of Using a Website Crawler?
The search engine index is a list where the search engine’s data is stored, allowing it to produce the search engine results page (SERP). Without this index, search engines would take considerably longer to generate results. Each time one makes a query, the search engine would have to go through every single website and page (or other data) relating to the keyword(s) used in your search. Not only that, but it would also have to follow up on any other information each page has access to—including backlinks, internal site links, and the like—and then make sure the results are structured in a way to present the most relevant information first.
This finding means that without a website crawler, each time you type a query into your search bar tool, the search engine would take minutes (if not hours) to produce any results. While this is an obvious benefit for users, what is the advantage for site owners and managers?
Using the algorithm as mentioned above, the website crawler reviews sites for the above information and develops a database of search strings. These strings include keywords and operators, which are the search commands used (and which are usually archived per IP address). This database is then uploaded to the search engine index to update its information, accommodating new sites and recently updated site pages to ensure fair (but relevant) opportunity.
Crawlers, therefore, allow for businesses to submit their sites for review and be included in the SERP based on the relevancy of their content. Without overriding current search engine ranking based on popularity and keyword strength, the website crawler offers new and updated sites (and pages) the opportunity to be found online. Not only that, but it allows you to see where your site’s SEO ranking can be improved.
How to Choose a Website Crawler?
Site crawlers have been around since the early 90s. Since then, hundreds of options have become available, each varying in usability and functionality. New website crawlers seem to pop up every day, making it an ever-expanding market. But, developing an efficient website crawler isn’t easy—and finding the right option can be overwhelming, not to mention costly if you happen to pick the wrong one.
Here are seven things to look out for in a website crawler:
Scalability – As your business and your site grow bigger, so do your requirements for the crawler to perform. A good site crawler should be able to keep up with this expansion, without slowing you down.
Transparency – You want to know exactly how much you’re paying for your website crawler, not run into hidden costs that can potentially blow your budget. If you can understand the pricing plan easily, it’s a safe bet: compact packages often have those unwanted hidden costs.
Reliability – A static site is a dead site. You’ll be making changes to your site on a fairly regular basis, whether it’s regarding adding (or updating) content or redesigning your layout. A good website crawler will monitor these changes, and update its database accordingly.
Anti-crawler mechanisms – Some sites have anti-crawling filters, preventing most website crawlers from accessing their data. As long as it remains within limits defined in the SRE (which a good website crawler should do anyway), the software should be able to bypass these mechanisms to gather relevant information accurately.
Data delivery – You may have a particular format you want to view the website crawler’s collected information. While you do get some programs that focus on specific data formats, you won’t go wrong finding one capable of multiple formats.
Support – No matter how advanced you are, chances are you’re going to need some help optimizing your website crawler’s performance, or even making sense of the output when starting out. Website crawlers with a good support system relieve a lot of unnecessary stress, especially when things go wrong once in awhile.
Data quality – Because the information gathered by website crawlers is initially as unstructured as the web would be without them, it’s imperative that the software you ultimately decide on is capable of cleaning it up and presenting it in a readable manner.
Now that you know what to look for in a website crawler, it’s time we made things easier for you by narrowing your search down from (literally) thousands to the best 60 options.
1. DYNO Mapper
With a focus on sitemap building (which the website crawler feature uses to determine which pages it’s allowed to read), DYNO Mapper is an impressive and functional software option.
DYNO Mapper’s website crawler lets you enter the URL (Uniform Resource Locator—the website address, such as) of any site and instantly discover its site map, and build your own automatically.
There are three packages to choose from, each allowing a different number of projects (sites) and crawl limitations regarding the number of pages scanned. If you’re only interested in your site and a few competitors, the Standard package (at $40 a month paid annually) is a good fit. However, the Organization ($1908 per year) and Enterprise ($4788 a year) packages are better options for higher education and medium to large sized companies, especially those who want to be able to crawl numerous sites and up to 200, 000 pages per crawl.
2. Screaming Frog SEO Spider
Screaming Frog offers a host of search engine optimization tools, and their SEO Spider is one of the best website crawlers available. You’ll instantly find where your site needs improvement, discovering broken links and differentiating between temporary and permanent redirects.
While their free version is somewhat competent, to get the most out of the Screaming Frog SEO Spider tool, you’ll want to opt for the paid version. Priced at about $197 (paid on an annual basis), it allows for unlimited pages (memory dependent) as well as a host of functions missing from the free version. These include crawl configuration, Google Analytics integration, customized data extraction, and free technical support.
Screaming Frog claim that some of the biggest sites use their services, including Apple, Disney, and even Google themselves. The fact that they’re regularly featured in some of the top SEO blogs goes a long way to promote their SEO Spider.
3. DeepCrawl
DeepCrawl is something of a specialized website crawler, admitting on their homepage that they’re not a “one size fits all tool. ” They offer a host of solutions, however, which you can integrate or leave out as you choose, depending on your needs. These include regular crawls for your site (which can be automated), recovery from Panda and (or) Penguin penalties, and comparison to your competitors.
There are five packages to choose from, ranging from $864 annually (you get one month free by opting for an annual billing cycle) to as high as $10 992 a year. Their corporate package, which offers the most features, is individually priced, and you’ll need to contact their support team to work out a cost.
Overall, the Agency package ($5484 a year) is their most affordable option for anyone wanting telephonic support and three training sessions. However, the Consultant plan ($2184 annually) is quite capable of meeting most site owners’ needs and does include email support.
4. Apifier
Designed to extract the site map and data from websites, Apifier processes information in a readable format for you surprisingly quickly (they claim to do so in a matter of seconds, which is impressive, to say the least).
It’s an especially useful tool for monitoring your competition and building/reforming your site. Although geared toward developers (the software requires some knowledge of JavaScript), they do offer the services of Apifier Experts to assist everyone else in making use of the tool. Because it’s cloud-based, you also won’t have to install or download any plugins or tools to use the software—you can work straight from your browser.
Developers do have the option of signing up for free, but the package does not entail all the basics. To get the best out of Apifier, you’ll want to opt for the Medium Business plan at $1548 annually ($129 a month), but the Extra Small option at $228 annually is also quite competent.
5. OnCrawl
Since Google understands only a portion of your site, OnCrawl offers you the ability to read all of it with semantic data algorithms and analysis with daily monitoring.
The features available include SEO audits, which can help you improve your site’s search engine optimization and identify what works and what doesn’t. You’ll be able to see exactly how your SEO and usability is affecting your traffic (number of visitors). OnCrawl even monitors how well Google can read your site with their crawler and will help you to improve and control what does and doesn’t get read.
With OnCrawl’s Starter package ($136 a year) affords you a 30-day money back guarantee, but it’s so limited you’ll likely be upgrading to one of the bigger packages that don’t offer the same money-back guarantee. Pro will set you back $261 a year—you get two months free with the annual plan—but will also cover almost every requirement.
6. SEO Chat Website Crawler and XML Site Map Builder
We now start moving away from the paid website crawlers to the free options available, starting with the SEO Chat Website Crawler and XML Site Map Builder. Also referred to as SEO Chat’s Ninja Website Crawler Tool, the online software mimics the Google sitemap generator to scan your site. It also offers spell checking and identifies page errors, such as broken links.
It’s incredibly easy to use integrate with any number of SEO Chat’s other free online SEO tools. After entering the site URL—either typing it out or using copy/paste—you can choose whether you want to scan up to 100, 500, or 1000 pages from the site.
Of course, there are some limitations in place. You’ll have to register (albeit for free) if you want the tool to crawl more than 100 pages, and you can only run five scans a day.
7. Webmaster World Website Crawler Tool and Google Sitemap Builder
The Webmaster World Website Crawler Tool and Google Sitemap Builder is another free scanner available online. Designed and developed in a very similar manner to the SEO Chat Ninja Website Crawler Tool above, it also allows you to punch in (or copy/paste) a site URL and opt to crawl up to 100, 500, or 1000 of its pages. Because the two tools have been built using almost the same code, it comes as no surprise that you’ll need to register for a free account if you want it to scan more than 100 pages.
Another similarity is that it can take up to half an hour to complete a website crawl, but allows you to receive the results via email. Unfortunately, you’re still limited to five scans per day.
However, where the Webmaster World tool does outshine the SEO Chat Ninja is in its site builder capabilities. Instead of being limited to XML, you’ll be able to use HTML too. The data provided is also interactive.
8. Rob Hammond’s SEO Crawler
Rob Hammond offers a host of architectural and on-page search engine optimization tools, one of which is a highly efficient free SEO Crawler. The online tool allows you to scan website URLs on the move, being compatible with a limited range of devices that seem to favor Apple products. There are also some advanced features that allow you to include, ignore, or even remove regular expressions (the search strings we mentioned earlier) from your crawl.
Results from the website crawl are in a TSV file, which can be downloaded and used with Excel. The report includes any SEO issues that are automatically discovered, as well as a list of the total external links, meta keywords, and much more besides.
The only catch is that you can only search up to 300 URLs for free. It isn’t made clear on Hammond’s site whether this is tracked according to your IP address, or if you’ll have to pay to make additional crawls—which is a disappointing omission.
9.
is easily the most obviously titled tool on our list, and the site itself seems a little overly simplistic, but it’s quite functional. The search function on the site’s homepage is a little deceptive, acting as a search engine would and bringing up results of the highest ranking pages containing the URL you enter. At the same time, you can see the genius of this though—you can immediately see which pages are ranking better than others, which allows you to quickly determine which SEO methods are working the best for your sites.
One of the great features of is that you can integrate it into your site, allowing your users to benefit from the tool. By adding a bit of HTML code to your site (which they provide for you free of charge as well), you can have the tool appear on your site as a banner, sidebar, or text link.
10. Web Crawler by Diffbot
Another rather simply named online scanner, the Web Crawler by Diffbot is a free version of the API Crawlbot included in their paid packages. It extracts information on a range of features of pages. The data contained are titles, text, HTML coding, comments, date of publication, entity tags, author, images, videos, and a few more.
While the site claims to crawl pages within seconds, it can take a few minutes if there’s a lot of internal links on your site. There’s an ill-structured web results page that can be viewed online, but you can also download the report in one of two formats: CSV or JSON.
You’re also limited in the number of searches, but it isn’t stipulated as to exactly what that limitation is—although you can share the tool on social media to gain 300 more crawls before being prompted to sign up for a 14-day free trial for any of Diffbot’s paid packages.
11. The Internet Archive’s Heritrix
The Internet Archive’s Heritrix is the first open source website crawler we’ll be mentioning. Because it (and, in fact, the rest of the crawlers that follow it on our list) require some knowledge of coding and programming languages. Hence, it’s not for everyone, but still well worth the mention.
Named after an old English word for an heiress, Heritrix is an archival crawler project that works off the Linux platform using JavaScript. The developers have designed Heritrix to be SRE compliant (following the rules stipulated by the Standard for Robot Exclusion), allowing it to crawl sites and gather data without disrupting site visitor experience by slowing the site down.
Everyone is free to download and use Heritrix, for redistribution and (or) modification (allowing you to build your website crawler using Heritrix as a foundation), within the limitations stipulated in the Apache License.
12. Apache Nutch
Based on Apache Lucene, Apache Nutch is a somewhat more diversified project than Apache’s older version. Nutch 1. x is a fully developed cross-platform JavaScript website crawler available for immediate use. It relies on another of Apache’s tools, Hadoop, which makes it suitable for batch processing—allowing you to crawl several URLs at once.
Nutch 2. x, on the other hand, stems from Nutch 1. x but is still being processed (it’s still usable, however, and one can use it as a foundation for developing your website crawler). The key difference is that Nutch 2. x uses Apache Gora, allowing for the implementation of a more flexible model/stack storage solution.
Both versions of Apache Nutch are modular and provide interface extensions like parsing, indexation, and a scoring filter. While it’s capable of running off a single workstation, Apache does recommend that users run it on a Hadoop cluster for maximum effect.
13. Scrapy
Scrapy is a collaborative open source website crawler framework, designed with Python for cross-platform use. Developed to provide the basis for a high-level web crawler tool, Scrapy is capable of performing data mining as well as monitoring, with automated testing. Because the coding allows for requests to be submitted and processed asynchronously, you can run multiple crawl types—for quotes, for keywords, for links, et cetera—at the same time. If one request fails or an error occurs, it also won’t interfere with the other crawls running at the same time.
This flexibility allows for very fast crawls, but Scrapy is also designed to be SRE compliant. Using the actual coding and tutorials, you can quickly set up waiting times, limits on the number of searches an IP range can do in a given period, or even restrict the number of crawls done on each domain.
14. DataparkSearch Engine
Developed using C++ and compatible on several platforms, DataparkSearch Engine is designed to organize search results in a website, group of websites, local systems, and intranets. Some of the key features include HTTP,, FTP, NNTP, and news URL scheme support, as well as an htdb URL for SQL database indexation. DataparkSearch Engine is also able to index text/plain, text/XML, text/HTML, audio/MPEG, and image/gif types natively, as well as multilingual websites and pages with content negotiation.
Using the vector calculation, results can be sorted by relevancy. Popularity ranking reports are classified as “Goo, ” which adds weight to incoming links, as well as “Neo, ” based on the neutral network model. You can also view your results according to the last time a site or page has been modified, or by a combination of relevancy and popularity rank to determine its importance. DataparkSearch Engine also allows for a significant reduction in search times by incorporating active caching mechanisms.
15. GNU Wget
Formed as a free software package, GNU Wget leans toward retrieving information on the most common internet protocols, namely HTTP, HTTPS, and FTP. Not only that, but you’ll also be able to mirror a site (if you so wish) using some of GNU Wget’s many features.
If a download of information and files is interrupted or aborted for any reason, using the REST and RANGE commands, allow you to resume the process with ease quickly. GNU Wget uses NSL-based message files, making it suitable for a wide array of languages, and can utilize wildcard file names.
Downloaded documents will be able to interconnect locally, as GNU Wget’s programming allows you to convert absolute links to relative links.
GNU Wget was developed with the C programming languages and is for use on Linux servers (but compatible with other UNIX operating systems, such as Windows).
16. Grub Next Generation
Designed as a website crawling software for clients and servers, Grub Next Generation assists in creating and updating search engine indexes. It makes it a viable option for anyone developing their search engine platform, as well as those looking to discover how well existing search engines can crawl and index their site.
It’s also operating system independent, making it a cross-platform program, and can be implemented in coding schemes using Perl, Python, C, and C# alike. The program also translates into several languages, namely Dutch, Galician, German, French, Spanish, Polish, and Finnish.
The most recent update included two new features, allowing users to alter admin upload server settings as well as adding more control over client usage. Admittedly, this update was as far back as mid-June 2011, and Freecode (the underlying source of Grub Next Generation platform) stopped providing updates three years later. However, it’s still a reliable web crawling tool worth the mention.
17. HTTrack Website Copier
The HTTrack Website Copier is a free, easy-to-use offline website crawler developed with C and C++. Available as WinHTTrack for Windows 2000 and up, as well as WebHTTrack for Linux, UNIX, and BSD, HTTrack is one of the most flexible cross-platform software programs on the market.
Allowing you to download websites to your local directory, HTTrack allows you to rebuild all the directories recursively, as well as sourcing HTML, images, and other files. By arranging the site’s link structure relatively, you’ll have the freedom of opening the mirrored version in your browser and navigate the site offline.
Furthermore, if the original site is updated, HTTrack will pick up on the modifications and update your offline copy. If the download is interrupted at any point for any reason, the program is also able to resume the process automatically.
HTTrack has an impressive help system integrated as well, allowing you to mirror and crawl sites without having to worry if anything goes wrong.
18. Norconex Collectors
Available as an HTTP Collector and a Filesystem Collector, the Norconex Collectors are probably the best open source website crawling solutions available for download.
JavaScript based, Norconex Collectors are compatible with Windows, Linux, Unix, Mac, and other operating systems that support Java. And if you need to change platforms at any time, you’ll be able to do so without any issues.
Although designed for developers, the programs are often extended by integrators and (while still being easily modifiable) can be used comfortably by anyone with limited developing experience too. Using one of their readily available Committers, or building your own, Norconex Collectors allow you to make submissions to any search engine you please. And if there’s a server crash, the Collector will resume its processes where it left off.
The HTTP Collector is designed for crawling website content for building your search engine index (which can also help you to determine how well your site is performing), while the Filesystem Collector is geared toward collecting, parsing, and modifying information on local hard drives and network locations.
19. OpenSearchServer
While OpenSearchServer also offers cloud-based hosting solutions (starting at $228 annually on a monthly basis and ranging up to $1428 for the Pro package), they also provide enterprise-class open source search engine software, including search functions and indexation.
You can opt for one of six downloadable scripts. The Search code, made for building your search engine, allows for full text, Boolean, and phonetic queries, as well as filtered searches and relevance optimization. The index includes seventeen languages, distinct analysis, various filters, and automatic classification. The Integration script allows for index replication, periodic task scheduling, and both REST API and SOAP web services. Parsing focuses on content file types such as Microsoft Office Documents, web pages, and PDF, while the Crawler code includes filters, indexation, and database scanning.
The sixth option is Unlimited, which includes all of the above scripts in one fitting space. You can test all of the OpenSearchServer code packages online before downloading. Written in C, C++, and Java PHP, OpenSearchServer is available cross-platform.
20. YaCy
A free search engine program designed with Java and compatible with many operating systems, YaCy was developed for anyone and everyone to use, whether you want to build your search engine platform for public or intranet queries.
YaCy’s aim was to provide a decentralized search engine network (which naturally includes website crawling) so that all users can act as their administrator. Period means that search queries are not stored, and there is no censoring of the shared index’s content either.
Contributing to a worldwide network of peers, YaCy’s scale is only limited by its number of active users. Nevertheless, it is capable of indexation billions of websites and pages.
Installation is incredibly easy, taking only about three minutes to complete—from download, extraction, and running the start script. While the Linux and Debian versions do require the free OpenJDK7 runtime environment, you won’t need to install a web server or any databases—all of that is included in the YaCy download.
21. htDig
Written with C++ for the UNIX operating system, htDig is somewhat outdated (their last patch released in 2004), but is still a convenient open source search and website crawling solution.
With the ability to act as a www browser, htDig will search servers across the web with ease. You can also customize results pages for the htDig search engine platform using HTML templates, running Boolean and “fuzzy” search types. It’s also completely compliant with the rules and limitations set out for website crawlers in the Standard for Robot Exclusion.
Using (or at least setting up) htDig does require a UNIX machine and both a C and C++ compiler. If you use Linux, however, you can also make use of the open source tool by also installing libstdc++ and using GCC and (or) g++ instead.
You’ll also have to ensure you have a lot of free space for the databases. While there are no means of calculating exactly how much disk space you’ll need, the databases tend to take about 150MB per 13 000 documents.
22. mnoGoSearch
mnoGoSearch isn’t very well documented, but it’s a welcome inclusion to our list (despite having seen no update since December 2015). Built with the C programming language, and originally designed for Windows only, mnoGoSearch has since expanded to include UNIX as well and offers a PHP front-end. It includes a site mirroring function, built-in parsers for HTML, XML, text, RTF, Docx, eml, mht, and MP3 file types, and support for HTTP, HTTPS, FTP, news, and nntp (as well as proxy support for both HTTP and HTTPS).
A whole range of database types, ranging from the usual MySQL and MSSQL to PostgreSQL and SQLite, can be used for storage purposes. With HTBD (the virtual URL scheme support), you can build a search engine index and use mnoGoSearch as an external full-text search solution in database applications for scanning large text fields.
mnoGoSearch also complies with the regulations set for website crawlers in the Standard for Robot Exclusion.
23. Uwe Hunfeld’s PHP Crawler
An object oriented library by Uwe Hunfeld, PHP Crawl can be used for website and website page crawling under several different platform parameters, including the traditional Windows and Linux operating systems.
By overriding PHP Crawl’s base class to implement customized functionality for the handleDocumentInfo and handleHeaderInfo features, you’ll be able to create your website crawler using the program as a foundation. In this way, you’ll not only be able to scan each website page but control the crawl process and include manipulation functions to the software. A good example of crawling code that can be implemented in PHP Crawl to do so is available at Dev Dungeon, who also provide open source coding to add a PHP Simple HTML DOM one-file library. This option allows you to extract links, headings, and other elements for parsing.
PHP Crawl is for developers, but if you follow the tutorials provided by Dev Dungeon a basic understanding of PHP coding will suffice.
24. WebSPHINX
Short for Website-Specific Processors for HTML Information Extraction, WebSPHINX provides an interactive cross-platform interactive development source for building web crawlers, designed with Javascript. It is made up of two parts, namely the Crawler Workbench and WebSPHINX Class Library.
Using the Crawler Workbench allows you to design and control a customized website crawler of your own. It allows you to visualize groups of pages as a graph, save website pages to your PC for offline viewing, connect pages together to read and (or) print them as one document and extract elements such as text patterns.
Without the WebSPHINX Class Library, however, none of it would be possible, as it’s your source for support in developing your website crawler. It offers a simple application framework for website page retrieval, tolerant HTML parsing, pattern matching, and simple HTML transformations for linking pages, renaming links, and saving website pages to your disk.
The standard for Robot Exclusion-compliant, WebSPHINX is one of the better open source website crawlers available.
25. WebLech
While in pre-Alpha mode back in 2002, Tom Hey made the basic crawling code for WebLech available online once it was functional, inviting interested parties to become involved in its development.
Now a fully featured Java based tool for downloading and mirroring websites, WebLech can emulate the standard web-browser behavior in offline mode by translating absolute links into relative links. Its website crawling abilities allow you to build a general search index file for the site before downloading all its pages recursively.
If it’s your site, or you’ve been hired to edit someone else’s site for them, you can re-publish changes to the web.
With a host of configuration features, you can set URL priorities based on the website crawl results, allowing you to download the more interesting/relevant pages first and leaving the less desirable one for last—or leave them out of the download altogether.
26. Arale
Written in 2001 by an anonymous developer who wanted to familiarize himself/herself with the package, Arale is no longer actively managed. However, the website crawler does work very well, as testified by some users, although one unresolved issue seems to be an OutofMemory Exception error.
On a more positive note, however, Arale is capable of downloading and crawling more than one user-defined file at a time without using all of your bandwidth. You’ll also have the ability to rename dynamic resources and code file names with query strings, as well as set your minimum and maximum file size.
While there isn’t any real support systems, user manuals, or official tutorials available for using Arale, the community has put together some helpful tips—including alternative coding to get the program up and running on your machine.
As it is comma

How to Crawl a Website with DeepCrawl
Running frequent and targeted crawls of your website is a key part of improving it’s technical health and improving rankings in organic search. In this guide, you’ll learn how to a crawl a website efficiently and effectively with DeepCrawl. The six steps to crawling a website include:
Configuring the URL sources
Understanding the domain structure
Running a test crawl
Adding crawl restrictions
Testing your changes
Running your crawl
Step 1: Configuring the URL sources
There are six types of URL sources you can include in your DeepCrawl projects.
Including each one strategically, is the key to an efficient, and comprehensive crawl:
Web crawl: Crawl only the site by following its links to deeper levels.
Sitemaps: Crawl a set of sitemaps, and the URLs in those sitemaps. Links on these pages will not be followed or crawled.
Analytics: Upload analytics source data, and crawl the URLs, to discover additional landing pages on your site which may not be linked. The analytics data will be available in various reports.
Backlinks: Upload backlink source data, and crawl the URLs, to discover additional URLs with backlinks on your site. The backlink data will be available in various reports.
URL lists: Crawl a fixed list of URLs. Links on these pages will not be followed or crawled.
Log files: Upload log file summary data from log file analyser tools, such as Splunk and
Ideally, a website should be crawled in full (including every linked URL on the site). However, very large websites, or sites with many architectural problems, may not be able to be fully crawled immediately. It may be necessary to restrict the crawl to certain sections of the site, or limit specific URL patterns (we’ll cover how to do this below).
Step 2: Understanding the Domain Structure
Before starting a crawl, it’s a good idea to get a better understanding of your site’s domain structure:
Check the www/non-www and / configuration of the domain when you add the domain.
Identify whether the site is using sub-domains.
If you are not sure about sub-domains, check the DeepCrawl “Crawl Subdomains” option and they will automatically be discovered if they are linked.
Step 3: Running a Test Crawl
Start with a small “Web Crawl, ” to look for signs that the site is uncrawlable.
Before starting the crawl, ensure that you have set the “Crawl Limit” to a low quantity. This will make your first checks more efficient, as you won’t have to wait very long to see the results.
Problems to watch for include:
A high number of URLs returning error codes, such as 401 access denied
URLs returned that are not of the correct subdomain – check that the base domain is correct under “Project Settings”.
Very low number of URLs found.
A large number of failed URLs (502, 504, etc).
A large number of canonicalized URLs.
A large number of duplicate pages.
A significant increase in the number of pages found at each level.
To save time, and check for obvious problems immediately, download the URLs during the crawl:
Step 4: Adding Crawl Restrictions
Next, reduce the size of the crawl by identifying anything that can be excluded. Adding restrictions ensures you are not wasting time (or credits) crawling URLs that are not important to you. All the following restrictions can be added within the “Advanced Settings” tab.
Remove Parameters
If you have excluded any parameters from search engine crawls with URL parameter tools like Google Search Console, enter these in the “Remove Parameters” field under “Advanced Settings. ”
Add Custom Settings
DeepCrawl’s “Robots Overwrite” feature allows you to identify additional URLs that can be excluded using a custom file – allowing you to test the impact of pushing a new file to a live environment.
Upload the alternative version of your robots file under “Advanced Settings” and select “Use Robots Override” when starting the crawl:
Filter URLs and URL Paths
Use the “Included/Excluded” URL fields under “Advanced Settings” to limit the crawl to specific areas of interest.
Add Crawl Limits for Groups of Pages
Use the “Page Grouping” feature, under “Advanced Settings, ” to restrict the number of URLs crawled for groups of pages based on their URL patterns.
Here, you can add a name.
In the “Page URL Match” column you can add a regular expression.
Add a maximum number of URLs to crawl in the “Crawl Limit” column.
URLs matching the designated path are counted. When the limits have been reached, all further matching URLs go into the “Page Group Restrictions” report and are not crawled.
Step 5: Testing Your Changes
Run test “Web Crawls” to ensure your configuration is correct and you’re ready to run a full crawl.
Step 6: Running your Crawl
Ensure you’ve increased the “Crawl Limit” before running a more in-depth crawl.
Consider running a crawl with as many URL sources as possible, to supplement your linked URLs with XML Sitemap and Google Analytics, and other data.
If you have specified a subdomain of www within the “Base Domain” setting, subdomains such as blog or default, will not be crawled.
To include subdomains select “Crawl Subdomains” within the “Project Settings” tab.
Set “Scheduling” for your crawls and track your progress.
Handy Tips
Settings for Specific Requirements
If you have a test/sandbox site you can run a “Comparison Crawl” by adding your test site domain and authentication details in “Advanced Settings. ”
For more about the Test vs Live feature, check out our guide to Comparing a Test Website to a Live Website.
To crawl an AJAX-style website, with an escaped fragment solution, use the “URL Rewrite” function to modify all linked URLs to the escaped fragment format.
Read more about our testing features – Testing Development Changes Before Putting Them Live.
Changing Crawl Rate
Watch for performance issues caused by the crawler while running a crawl.
If you see connection errors, or multiple 502/503 type errors, you may need to reduce the crawl rate under “Advanced Settings. ”
If you have a robust hosting solution, you may be able to crawl the site at a faster rate.
The crawl rate can be increased at times when the site load is reduced – 4 a. m. for example.
Head to “Advanced Settings” > “Crawl Rate” > “Add Rate Restriction. ”
Analyze Outbound Links
Sites with a large quantity of external links, may want to ensure that users are not directed to dead links.
To check this, select “Crawl External Links” under “Project Settings, ” adding an HTTP status code next to external links within your report.
Read more on outbound link audits to learn about analyzing and cleaning up external links.
Change User Agent
See your site through a variety of crawlers’ eyes (Facebook/Bingbot etc. ) by changing the user agent in “Advanced Settings. ”
Add a custom user agent to determine how your website responds.
After The Crawl
Reset your “Project Settings” after the crawl, so you can continue to crawl with ‘real-world’ settings applied.
Remember, the more you experiment and crawl, the closer you get to becoming an expert crawler.
Start your journey with DeepCrawl
If you’re interested in running a crawl with DeepCrawl, discover our range of flexible plans or if you want to find out more about our platform simply drop us a message and we’ll get back to you asap.
Author
Sam Marsden
Sam Marsden is Deepcrawl’s Former SEO & Content Manager. Sam speaks regularly at marketing conferences, like SMX and BrightonSEO, and is a contributor to industry publications such as Search Engine Journal and State of Digital.
Frequently Asked Questions about website crawling tools
How do I crawl an entire website?
The six steps to crawling a website include:Configuring the URL sources.Understanding the domain structure.Running a test crawl.Adding crawl restrictions.Testing your changes.Running your crawl.
Is it legal to crawl a website?
If you’re doing web crawling for your own purposes, it is legal as it falls under fair use doctrine. The complications start if you want to use scraped data for others, especially commercial purposes. … As long as you are not crawling at a disruptive rate and the source is public you should be fine.Jul 17, 2019
What does the crawl website command do?
Web crawlers can automate maintenance tasks on a website such as validating HTML or checking links. HTML validators, also referred to as quality assurance programs, are used to check whether HTML mark-up elements have any syntax errors. … Web crawlers can also be used to download all the content from a website.Jun 17, 2020
