Web Scraper To Csv
Data Export | Web Scraper Documentation
Web Scraper browser extension supports data export in CSV format while Web Scraper Cloud supports data export in CSV, XLSX and JSON formats.
XLSX and JSON formats will be added to Web Scraper extension in a future release.
Data export from Web Scraper Extension
Download scraped data via Export data as CSV menu selection under the Sitemap menu. Data can be also downloaded while the scraper is running.
Download data from Web Scraper Cloud
Download scraped data via website from Jobs or Sitemaps sections. Data can be also downloaded while the scraper is running.
Automated data export
Set up automated data export to Dropbox via Data Export section. Currently exported data will be in CSV format. Data will be exported to Apps/Web Scraper in your Dropbox folder.
Data export via API
Additionally, you can download data via Web Scraper Cloud API in CSV or JSON formats.
Data format file structure and limitations
XLSX
Data in separate cells is limited to 32767 characters.
Additional characters will be cut off.
Use other export formats if large text contents are expected in a single cell.
Row count is limited to 1 million rows.
In case data set contains more than 1 million rows, the data will be split into multiple sub sheets.
JSON
JSON file format contains one JSON record per line.
New line characters found in data will be escaped as “\n” so \n character can be safely used as a record separator.
Note! Parsing the entire file as a JSON string will not work since all records are not wrapped in a JSON array.
This was a design decision to make it easier to parse large files.
CSV
Comma Separated Values files format is formatted as described in RFC 4180 standard.
Values are quoted in double quotes ” and in case when a double quote character is in text it is escaped with another double quote character.
Lines are separated with CR+LF \r\n characters.
Additionally CSV files include byte order mark (BOM) U+FEFF characters at the beginning of the file to hint that the file will be in UTF-8 format.
New line characters are not escaped which means using \r\n as a record separator can result in errors.
We recommend using a CSV reader library when reading CSV files programmatically.
Opening CSV file with a spreadsheet program
We recommend using Libre Office Calc when opening CSV files.
Microsoft office often is incorrectly interpreting CSV files formatted in RFC 4180 standard.
Mostly this is related to text including new line characters.
In case when a CSV file is incorrectly opened by Microsoft Excel try using data import feature:
Start with an empty file
Go to Data tab
Choose From Text/CSV
Open CSV file
Set up import settings – UTF-8 encoding, Comma delimiter, Do not detect data types
Load data

Easily Web Scraping with Pagination from yell.com to CSV file …
Dear reader, would you like to scrap directory sites like and do you want to save the results in CSV file format? If true, then consider this article to the end while enjoying a cup of your coffee. Enjoy:)I will share how I do web scraping quickly on directory websites such as in this case study, I will make this article brief but clear so that you do not get bored with long-winded doing so make sure you are on a new project in your python idle. I use Pycharm as python idle because it’s very easy and you have installed bs4 and requests. I did not explain how to install it here because I will only focus on how to do the scraping. please visit my previous article, there are ways on how to install the package and use the virtual environment. Thank you. 1. Import BeautifulSoup and Requests ModulIn the first line, we have to initialize the module that we will use so that the project can run well. That matter can be done by importing the bs4import requestsimport csv2. Create URL and header variablesIn the URL variable, we can create an input function that functions as the keyword that we are looking for. The header variable is filled with URL variable like as follows:url = ‘0}&location={1}&scrambleSeed=509559697&pageNum=1’(input(’Enter term: ‘), input(’Enter location:’))the headers variable like as follows:header = {‘User-Agent’: ‘Mozilla/5. 0 (Windows NT 10. 0; Win64; x64) AppleWebKit/537. 36 (KHTML, like Gecko) Chrome/80. 0. 3987. 149 Safari/537. 36’}Note: user-agent can be found on google by typing “whats my user-agent”. or you can click here to get it. 3. Create Product VariableBefore we do, we request by the method of getting it first and change the text format of the request to the bs4 = (url, headers= headers)soup = autifulSoup(, ‘’)Then, inspect the elements first in the browser that we use to find the class of the target that we are going to the picture each product is in the “div” tag and the “row businessCapsule — mainRow” class. For that we can use the “findAll” function in the beautifulsoup module to retrieve all information contained in the oduct = ndAll(‘div’, ‘row businessCapsule–mainRow’)4. Lopping the Product Variable with “for” FunctionThen we will parse the data contained in the product class by repeating the ‘for’ function. the data that I took in this article include name, address, telephone number and website. then you can develop your own by adding data variables that you will take and enter into the “find (‘

Web Scraper in Chrome – How to Web Scrape Using Chrome Extension
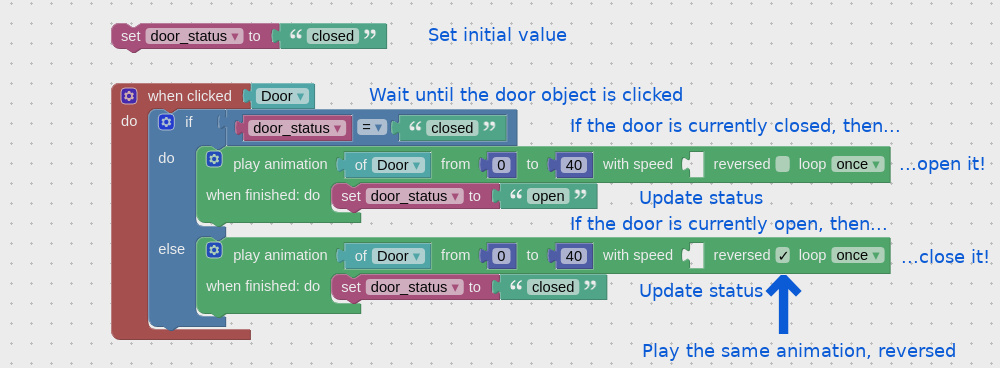
This is the continuation of the tutorial series on How to use web scraper chrome extension to extract data from the web. In the first part, we explained the basics of data scraping using web scraper. Once you have scraped enough data, you can close the popup window. This will stop the scraping process and the data scraped so far will be cached. You can browse the collected data by clicking on ‘browse’ option under ‘sitemap’. Let’s see what else can be done with the scraped data.
Exporting the Data to a CSV File
To export the extracted data to a CSV file, you can click on the ‘Sitemap’ tab and then select ‘Export data as CSV’. Click on the ‘Download now’ button and select your preferred save location. Now you should have your scraped data from the website in a CSV file.
The CSV file should have a column named gifs (our selector id) and several rows depending on the number of URLs scraped. Your CSV file should look similar to this.
It will have just one column with the same name as our selector id (gif) and many rows depending on the number of URls scraped.
Importing the Scraped Data into a MySQL Table
For convenience in handling the collected data while using it in a website, you might want to import the scraped data into a MySQL table. Now that we have the CSV file containing scraped data, it can be easily achieved using a few lines of code.
Create a new MySQL table with the same structure as our CSV file and name it ‘awesomegifs’. Only two columns are required in this case. An id column which would auto increment and the column for URLs. Here is the code for that.
Now all you have to do is execute the below SQL command after replacing the path of the CSV file with yours.
If everything went smoothly, you should have all of the scraped URLs from the CSV file inserted into your MySQL database and ready to be used. That’s it, you just learned to crawl a website with the web scraper chrome extension and even made a MySQL table out of it.
Now that you know how to set up the web scraper extension to crawl and extract image URLs from, you can try scraping other sites too. Obviously, you will first have to spend some time figuring out how to crawl a particular site since every site is different. Although the ‘selector’ tool lets you easily point and choose any element on the web page with a mouse click, it might not always give you the expected results. To get the more complicated websites scraped, you will also need to have some programming knowledge. Looking into the source code (CTRL+U), you should be able to find out the attributes of your required data in most cases.
After all, there is no scraping tool that can crawl data from every website out of the box. This is the main reason why businesses prefer custom web scraping services instead of DIY tools like the web scraper extension for chrome.
Web scraping tools aren’t for everyone. Tools can be a good option if you are a student or hobbyist looking for ways to collect some data without spending much money or learning complicated technology behind the serious kind of web scraping. If you are a business in need of data to gain competitive intelligence, tools wouldn’t be a reliable option. You are much better off with a dedicated web scraping service that can provide you just the data you need without the associated headaches.
Also, be warned that scraping certain websites can mean legal trouble for you. Some websites state that they don’t want to be scraped in their terms of use page or While running a scraper tool, it is your responsibility to make sure that you are not violating any rules or policies set by the website. When in doubt about the legal aspects of web scraping, you could read our blog post on the same.
Frequently Asked Questions about web scraper to csv
How do I scrape data from a website to a CSV file?
Let’s get StartedImport BeautifulSoup and Requests Modul. In the first line, we have to initialize the module that we will use so that the project can run well. … Create URL and header variables. … Create Product Variable. … Lopping the Product Variable with “for” Function. … Pagination. … Append the Data. … Save to CSV File.
How do I export data from web scraper?
To export the extracted data to a CSV file, you can click on the ‘Sitemap’ tab and then select ‘Export data as CSV’. Click on the ‘Download now’ button and select your preferred save location. Now you should have your scraped data from the website in a CSV file.Apr 20, 2016
Is it legal to scrape API?
It is perfectly legal if you scrape data from websites for public consumption and use it for analysis. However, it is not legal if you scrape confidential information for profit. For example, scraping private contact information without permission, and sell them to a 3rd party for profit is illegal.Aug 16, 2021