Webcrawler Search Engine
Where Are They Now? Search Engines We’ve Known & Loved
AltaVista, the Google of its day, is now to be gobbled up by Overture. It’s a famous name that’s seen better days. But AltaVista’s not the only major search player to have faded, as years have gone by. Come along and see the early search engines that have died, those that have been transformed, who’s survived and how the “new” players that are no longer so young are doing.
Of interest to history buffs will also be my The End For Search Engines? article, written at the beginning of 2001, when many assumed search engines were a dying breed (I argued differently). Also, see the Major Search Engines page for links to some of the services mentioned below and additional history.
Rest In Peace
Open Text (1995-1997): Yahoo’s original search partner was also a popular web search site of its own in 1995. The company crawled the web to gather listings, just as Google does today. Open Text decided to focus instead on enterprise search solutions, where it is currently successful. Web search operations closed in mid-1997.
Magellan (1995-2001): An early search engine that saw its popularity drop immediately after being purchased by Excite in mid-1996. It was closed in April 2001.
Infoseek (1995-2001): Launched in early 1995, Infoseek originally hoped to charge for searching. When that failed, the popular search engine shifted to depending like others on banner ads. Disney took a large stake in the company in 1998 and went down the “portal” path that other leading search engines had followed. The site was also renamed “Go. ” Its failure to make money caused Disney to stop Go’s own internal search capabilities abruptly in early 2001. Today, Go remains operating, powered by Google.
Snap (1997-2001): Launched by CNET in 1997, Snap first used Infoseek, then Inktomi, then created its own directory of human-edited listings that were coupled with clickthrough technology that ranked results in part by what people clicked on. NBC later acquired a majority interest in the company, then renamed it NBCi and intended to win the “portal wars” with the site. But as with Disney and Infoseek, the site’s internal search technology was abruptly closed in early 2001. It is currently powered by meta search results from Infospace.
Direct Hit (1998-2002): When Google first appeared as the hot new search technology in 1998, so did Direct Hit, featuring the ability to measure what people clicked on in search results as a way to make those better. It gained a deal with HotBot and was offered as a search feature on other portals such as Lycos and MSN. It was purchased by Ask Jeeves in 2000, then neglected over the following years. The site was formally closed in early 2002.
Ch-Ch-Ch-Changes
Lycos (1994; reborn 1999): Lycos operated one of the web’s earliest crawler-based search engines. Lycos stopped depending on that spider in 1999 and instead now outsources for its search results from AllTheWeb.
WebCrawler (1994; reborn 2001): WebCrawler still exists as a meta search engine that gets results from other search engines, rather than through its own efforts. Now owned by Infospace, WebCrawler was arguably the web’s first crawler-based search engine in the way we know them today. It launched in early 1994 as a University of Washington research project, was purchased by AOL in 1995, then sold to Excite at the end of 1996. The WebCrawler spider was deactivated in December 2001.
Yahoo (1994; reborn 2002): Before Google, before AltaVista, there was Yahoo. Despite all the changes in the search space over the years, Yahoo has remained one of the most popular search destinations on the web. Yahoo stood out from its early competitors by using humans to catalog the web, a directory system. Crawler-based results from its partners only kicked in if there were no human-powered matches. That actually made Yahoo more relevant than competitors for many years, until the Google-era ushered in crawler-based results that were both comprehensive and highly relevant. Yahoo caught up with that era in October 2002, when it dropped its human-powered results in preference to Google’s results. The Yahoo Directory still exists and is leveraged by the company, but today’s Yahoo is a far different creature than what it was for all those years before.
Excite (1995; reborn 2001): Quickly gaining popularity after launching in late 1995, Excite crawled the web to gather listings. In 1996, the company bought two rivals, Magellan and WebCrawler, then itself was transformed via a merger into [email protected] Excite stopped gathering its own listings in December 2001, in the wake of its parent company’s bankruptcy. Now a new “Excite Networks” company owns the Excite web site, while Infospace has a license to provide meta search results to Excite in perpetuity.
HotBot (1996; reborn 2002): Launched in May 1996, HotBot was initially powered by Inktomi and backed by Wired. HotBot’s wild colors, great results and impressive features drew acclaim. Lycos (now Terra Lycos) bought the service as part of Wired Digital in 1998. As the “other” Lycos search engine, it suffered from a lack of attention by its parent. Last December, it was revitalized as a meta-like search engine, offering access to results from four different major search engines: Google, FAST, Teoma and Inktomi.
Ask Jeeves (1998; reborn 2002): Originally hailed as the “natural language” search engine when it debuted in 1998, the secret to Ask Jeeves wasn’t really the ability to understand language. Instead, Ask Jeeves had over 100 editors monitoring what people searched for, then hand-selecting sites that seemed to best answer those queries. Such an approach is good for the most popular queries but doesn’t help when people want unusual information. Thus Ask purchased Direct Hit in early 2000, to make it more comprehensive. The company failed to capitalize on that technology, so tried again more successfully by purchasing Teoma in 2001. In 2002, it shifted over to relying on Teoma for nearly all of its matches.
Same As They Ever Were
AltaVista (1995-): The Google of its day, AltaVista offered access to a huge index of web sites, when it launched in December 1995. The search engine quickly grew in popularity, but its parent Digital didn’t know what to do with it. The sale of Digital to Compaq didn’t help matters, and the situation grew worse when AltaVista was spun into a separate company, majority-owned by CMGI. It was relaunched as a portal in October 1999, entering an already crowded field and taking its attention away from the quality of its search results. It paid the price as dissatisfied users flocked to newcomer Google. Throughout everything, AltaVista’s crawler has kept going. Overture now intends to buy the company.
LookSmart (1996-): Launched in 1996, LookSmart remains the only search company to heavily depend upon humans to gather its primary listings. In 2002, LookSmart bought the WiseNut crawler to complement its human-powered results. Few people search at the LookSmart site itself. Instead, LookSmart acts as a provider to others needing search results. Its major partner is MSN.
Overture (1998-): Formerly known as GoTo, the company launched a “paid placement” service in early 1998, where sites were ranked based in order of how much they were willing to pay. The web had matured enough by this point to accept this type of commercialization: similar plans tried by Open Text in 1996 were dropped after a chorus of complaints. By 2000, Overture abandoned its initial route of driving consumers to its own web site in favor of a network model of providing its paid listings to other sites. Today, it powers paid listings to major search engines such as MSN and Yahoo.
The New Breed
Google (1998-): Ironically, Google is now the oldest of the “new” players that have taken over from the old. Launched in 1998 as a Stanford University research project, Google’s ability to analyze links from across the web helped it produce a new generation of highly relevant, crawler-based results. By many different measures, it is today the most popular search engine in use.
AllTheWeb (1999-): It’s a strong rival to Google in terms of popularity, but AllTheWeb is nowhere near as popular with users. That was OK with parent company FAST. AllTheWeb was meant only to demonstrate the company’s ability to power the results of other search engines by crawling the web. AllTheWeb launched in May 1999 and counts Lycos as its major partner. Overture announced last month that it intends to acquire the search engine.
Teoma (2000-): Launched in 2000, Teoma is known for its own spin on analyzing links from across the web to generate highly relevant results. It was purchased by Ask Jeeves in September 2001 and continues on as its own site, as well as providing results to the Ask Jeeves site.
WiseNut (2001-): This service gained attention in 2001 and was snapped up by LookSmart in early 2002. The company has since been working to improve its technology and freshness, but the work still hasn’t finished.
The Powered By Others Bunch
AOL Search (1997-): AOL offers its own search engine to its members, which is currently powered by Google. Originally known as AOL NetFind, an AOL-branded search engine was first offered in 1997 and powered by Excite. AOL briefly owned its own web search technology, WebCrawler, but sold that to Excite in 1996.
MSN Search (1998-): Microsoft provides a search engine to those coming to the MSN site or searching via features within Internet Explorer. Plenty do, making MSN Search one of the most popular search engines on the web. The service has always outsourced for its search technology. It currently provides a mixture of results from LookSmart and Inktomi.

How to get rid of Webcrawler.com Redirect – virus removal guide …
redirect removal instructions
What is
is a high-quality Internet search engine very similar to sites such as Yahoo, Bing, Google, etc. The website itself is legitimate, however, it is used by browser-hijacking websites/applications that modify browser options and cause unwanted redirects.
Research shows that developers promote fake search engines to generate revenue. They employ various scripts and apps to modify browser options (typically, the homepage, new tab URL, and default search engine) by assigning them to a specific URL (a fake web search engine). These sites claim to significantly enhance the browsing experience, but in fact deliver no real value for regular users. Rather than generating improved results, sites such as simply redirect users to together with a pre-entered search query. These sites are promoted together with a number of third party applications/browser plug-ins (so-called “helper objects”). These apps/add-ons are used to prevent users from reverting the aforementioned changes – they reassign browser options when attempts are made to change them. Therefore, returning browsers to their previous states becomes impossible and users are encouraged to visit various sites (that redirect to) when they search via the URL bar or simply open a new browser tab. Another important issue is data tracking. Browser-hijacking sites/applications are typically designed to record user-system information (IP addresses, websites visited, pages viewed, search queries, keystrokes, geo-locations, etc. ) that includes personal information. Developers later share this information with third parties who generate revenue by misusing private details. Therefore, data tracking might lead to serious privacy issues or even identity theft. If you encounter redirects to suspicious websites (that lead to), immediately check the list of installed applications/browser plug-ins and eliminate any suspicious entries. Remember that is legitimate, but visiting this site through other rogue sites is not recommended – if you want to use as your web search engine, assign this URL directly, rather than using another website as a “gate”.
The Internet is full of fake search engines and browser-hijacking applications. These sites/apps often claim to provide “useful features”, but these false promises are merely attempts to give the impression of legitimacy. Fake search engines and browser hijackers are designed only to generate revenue for the developers. Rather than giving any real value for regular users, these apps/sites cause unwanted redirects and gather sensitive information, thereby posing a threat to your privacy and Internet browsing safety.
How did install on my computer?
Some fake search engines are promoted using browser-hijacking downloaders/installers set-ups that modify browser options while downloading/installing software. In addition, some are promoted via browser-hijacking applications that infiltrate systems without consent. These apps are proliferated using intrusive advertisements and a deceptive marketing method called “bundling”. Intrusive ads redirect to malicious sites and execute scripts that stealthily download/install potentially unwanted programs (PUPs) or even malware. “Bundling” is essentially stealth installation of third party apps with regular software. Many developers are not honest enough to disclose PUP installations properly. They hide them within “Custom/Advanced” options (or other sections) of the download/installation processes. Furthermore, many users are likely to skip download/installation steps and click various advertisements without understanding the possible consequences. In doing so, they expose their systems to risk of various infections and compromise their privacy.
How to avoid installation of potentially unwanted applications?
Lack of knowledge and careless behavior are the main reasons for computer infections. The key to safety is caution. Therefore, pay close attention when browsing the Internet and downloading/installing software. Bear in mind that intrusive ads often seem legitimate, but once clicked, redirect to dubious websites (such as adult dating, gambling, survey, and similar). They are typically delivered by adware-type PUPs. Therefore, if you experience suspicious redirects, immediately remove all dubious applications and browser plug-ins. Furthermore, carefully analyze each window of the download/installation dialogs using the “Custom” or “Advanced” settings. Opt-out of all additionally-included programs and decline offers to download/install them. Never use third party download/installation tools, since developers monetize them by promoting PUPs. Software should be downloaded from official sources only, using direct download links.
Instant automatic malware removal:
Manual threat removal might be a lengthy and complicated process that requires advanced computer skills. Combo Cleaner is a professional automatic malware removal tool that is recommended to get rid of malware. Download it by clicking the button below:
▼ DOWNLOAD Combo Cleaner
By downloading any software listed on this website you agree to our Privacy Policy and Terms of Use. To use full-featured product, you have to purchase a license for Combo Cleaner. 7 days free trial available. Combo Cleaner is owned and operated by Rcs Lt, the parent company of read more.
Quick menu:
STEP 1. Uninstall application using Control Panel.
STEP 2. Remove redirect from Internet Explorer.
STEP 3. Remove browser hijacker from Google Chrome.
STEP 4. Remove homepage and default search engine from Mozilla Firefox.
STEP 5. Remove redirect from Safari.
STEP 6. Remove rogue plug-ins from Microsoft Edge.
browser hijacker removal:
Windows 11 users:
Right-click on the Start icon, select Apps and Features. In the opened window search for the application you want to uninstall, after locating it, click on the three vertical dots and select Uninstall.
Windows 10 users:
Right-click in the lower left corner of the screen, in the Quick Access Menu select Control Panel. In the opened window choose Programs and Features.
Windows 7 users:
Click Start (Windows Logo at the bottom left corner of your desktop), choose Control Panel. Locate Programs and click Uninstall a program.
macOS (OSX) users:
Click Finder, in the opened screen select Applications. Drag the app from the Applications folder to the Trash (located in your Dock), then right click the Trash icon and select Empty Trash.
In the uninstall programs window: look for any recently installed suspicious applications, select these entries and click “Uninstall” or “Remove”.
After uninstalling the potentially unwanted programs that cause browser redirects to the website, scan your computer for any remaining unwanted components. To scan your computer, use recommended malware removal software.
browser hijacker removal from Internet browsers:
Video showing how to remove browser redirects:
Internet Explorer
Chrome
Firefox
Safari
Edge
Remove malicious add-ons from Internet Explorer:
Click the “gear” icon (at the top right corner of Internet Explorer), select “Manage Add-ons”. Look for any recently installed suspicious extensions, select these entries and click “Remove”.
Change your homepage:
Click the “gear” icon (at the top right corner of Internet Explorer), select “Internet Options”, in the opened window, remove hxxp and enter your preferred domain, which will open each time you launch Internet Explorer. You can also enter about: blank to open a blank page when you start Internet Explorer.
Change your default search engine:
Click the “gear” icon (at the top right corner of Internet Explorer), select “Manage Add-ons”. In the opened window, select “Search Providers”, set “Google”, “Bing”, or any other preferred search engine as your default and then remove “webcrawler”.
Optional method:
If you continue to have problems with removal of the browser hijacker, reset your Internet Explorer settings to default.
Windows XP users: Click Start, click Run, in the opened window type In the opened window click the Advanced tab, then click Reset.
Windows Vista and Windows 7 users: Click the Windows logo, in the start search box type and click enter. In the opened window click the Advanced tab, then click Reset.
Windows 8 users: Open Internet Explorer and click the gear icon. Select Internet Options.
In the opened window, select the Advanced tab.
Click the Reset button.
Confirm that you wish to reset Internet Explorer settings to default by clicking the Reset button.
Remove malicious extensions from Google Chrome:
Click the Chrome menu icon (at the top right corner of Google Chrome), select “Tools” and click “Extensions”. Locate all recently installed suspicious add-ons, select these entries and click the trash can icon.
Click the Chrome menu icon (at the top right corner of Google Chrome), select “Settings”. In the “On startup” section, click “set pages”, hover your mouse over hxxp and click the x symbol. Now, you can add your preferred website as your homepage.
To change your default search engine in Google Chrome: Click the Chrome menu icon (at the top right corner of Google Chrome), select “Settings”, in the “Search” section, click “Manage Search Engines… “, remove “” and add or select your preferred domain.
If you continue to have problems with removal of the browser hijacker, reset your Google Chrome browser settings. Click the Chrome menu icon (at the top right corner of Google Chrome) and select Settings. Scroll down to the bottom of the screen. Click the Advanced… link.
After scrolling to the bottom of the screen, click the Reset (Restore settings to their original defaults) button.
In the opened window, confirm that you wish to reset Google Chrome settings to default by clicking the Reset button.
Remove malicious plug-ins from Mozilla Firefox:
Click the Firefox menu (at the top right corner of the main window), select “Add-ons”. Click “Extensions” and remove all recently installed browser plug-ins.
To reset your homepage, click the Firefox menu (at the top right corner of the main window), then select “Options”, in the opened window, remove hxxp and enter your preferred domain, which will open each time you start Mozilla Firefox.
In the URL address bar, type about:config and press “I’ll be careful, I promise! ” the search filter at the top, type: “”Right-click on the found preferences and select “Reset” to restore default values.
Computer users who have problems with browser hijacker removal can reset their Mozilla Firefox settings.
Open Mozilla Firefox, at the top right corner of the main window, click the Firefox menu, in the opened menu, click Help.
Select Troubleshooting Information.
In the opened window, click the Refresh Firefox button.
In the opened window, confirm that you wish to reset Mozilla Firefox settings to default by clicking the Refresh Firefox button.
Remove malicious extensions from Safari:
Make sure your Safari browser is active and click Safari menu, then select Preferences…
In the preferences window select the Extensions tab. Look for any recently installed suspicious extensions and uninstall them.
In the preferences window select General tab and make sure that your homepage is set to a preferred URL, if its altered by a browser hijacker – change it.
In the preferences window select Search tab and make sure that your preferred Internet search engine is selected.
Make sure your Safari browser is active and click on Safari menu. From the drop down menu select Clear History and Website Data…
In the opened window select all history and click the Clear History button.
Remove malicious extensions from Microsoft Edge:
Click the Edge menu icon (at the top right corner of Microsoft Edge), select “Extensions”. Locate any recently-installed suspicious browser add-ons, and remove them.
Change your homepage and new tab settings:
Click the Edge menu icon (at the top right corner of Microsoft Edge), select “Settings”. In the “On startup” section look for the name of the browser hijacker and click “Disable”.
Change your default Internet search engine:
To change your default search engine in Microsoft Edge: Click the Edge menu icon (at the top right corner of Microsoft Edge), select “Privacy and services”, scroll to bottom of the page and select “Address bar”. In the “Search engines used in address bar” section look for the name of the unwanted Internet search engine, when located click the “Disable” button near it. Alternatively you can click on “Manage search engines”, in the opened menu look for unwanted Internet search engine. Click on the puzzle icon near it and select “Disable”.
If you continue to have problems with removal of the browser hijacker, reset your Microsoft Edge browser settings. Click the Edge menu icon (at the top right corner of Microsoft Edge) and select Settings.
In the opened settings menu select Reset settings.
Select Restore settings to their default values. In the opened window, confirm that you wish to reset Microsoft Edge settings to default by clicking the Reset button.
If this did not help, follow these alternative instructions explaining how to reset the Microsoft Edge browser.
Summary:
A browser hijacker is a type of adware infection that modifies Internet browser settings by assigning the homepage and default Internet search engine settings to some other (unwanted) website URL. Commonly, this type of adware infiltrates operating systems through free software downloads. If your download is managed by a download client, ensure that you decline offers to install advertised toolbars or applications that seek to change your homepage and default Internet search engine settings.
Removal assistance:If you are experiencing problems while trying to remove browser hijacker from your Internet browsers, please ask for assistance in our malware support forum.
Post a comment:If you have additional information on browser hijacker or it’s removal please share your knowledge in the comments section below.

How Do Search Engine Crawlers Work? – DeepCrawl
Now that you’ve got a top level understanding about how search engines work, let’s delve deeper into the processes that search engine and web crawlers use to understand the web. Let’s start with the crawling process.
What is Search Engine Crawling?
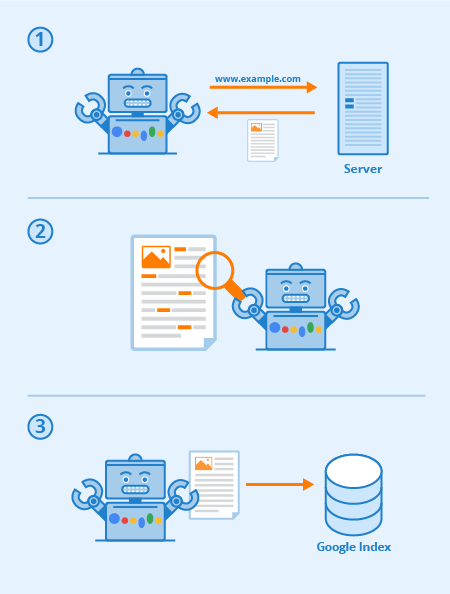
Crawling is the process used by search engine web crawlers (bots or spiders) to visit and download a page and extract its links in order to discover additional pages.
Pages known to the search engine are crawled periodically to determine whether any changes have been made to the page’s content since the last time it was crawled. If a search engine detects changes to a page after crawling a page, it will update it’s index in response to these detected changes.
How Does Web Crawling Work?
Search engines use their own web crawlers to discover and access web pages.
All commercial search engine crawlers begin crawling a website by downloading its file, which contains rules about what pages search engines should or should not crawl on the website. The file may also contain information about sitemaps; this contains lists of URLs that the site wants a search engine crawler to crawl.
Search engine crawlers use a number of algorithms and rules to determine how frequently a page should be re-crawled and how many pages on a site should be indexed. For example, a page which changes a regular basis may be crawled more frequently than one that is rarely modified.
How Can Search Engine Crawlers be Identified?
The search engine bots crawling a website can be identified from the user agent string that they pass to the web server when requesting web pages.
Here are a few examples of user agent strings used by search engines:
Googlebot User Agent
Mozilla/5. 0 (compatible; Googlebot/2. 1; +)
Bingbot User Agent
Mozilla/5. 0 (compatible; bingbot/2. 0; +)
Baidu User Agent
Mozilla/5. 0 (compatible; Baiduspider/2. 0; +)
Yandex User Agent
Mozilla/5. 0 (compatible; YandexBot/3. 0; +)
Anyone can use the same user agent as those used by search engines. However, the IP address that made the request can also be used to confirm that it came from the search engine – a process called reverse DNS lookup.
Crawling images and other non-text files
Search engines will normally attempt to crawl and index every URL that they encounter.
However, if the URL is a non-text file type such as an image, video or audio file, search engines will typically not be able to read the content of the file other than the associated filename and metadata.
Although a search engine may only be able to extract a limited amount of information about non-text file types, they can still be indexed, rank in search results and receive traffic.
You can find a full list of file types that can be indexed by Google available here.
Crawling and Extracting Links From Pages
Crawlers discover new pages by re-crawling existing pages they already know about, then extracting the links to other pages to find new URLs. These new URLs are added to the crawl queue so that they can be downloaded at a later date.
Through this process of following links, search engines are able to discover every publicly-available webpage on the internet which is linked from at least one other page.
Sitemaps
Another way that search engines can discover new pages is by crawling sitemaps.
Sitemaps contain sets of URLs, and can be created by a website to provide search engines with a list of pages to be crawled. These can help search engines find content hidden deep within a website and can provide webmasters with the ability to better control and understand the areas of site indexing and frequency.
Page submissions
Alternatively, individual page submissions can often be made directly to search engines via their respective interfaces. This manual method of page discovery can be used when new content is published on site, or if changes have taken place and you want to minimise the time that it takes for search engines to see the changed content.
Google states that for large URL volumes you should use XML sitemaps, but sometimes the manual submission method is convenient when submitting a handful of pages. It is also important to note that Google limits webmasters to 10 URL submissions per day.
Additionally, Google says that the response time for indexing is the same for sitemaps as individual submissions.
Next: Search Engine Indexing
Author
Sam Marsden
Sam Marsden is Deepcrawl’s Former SEO & Content Manager. Sam speaks regularly at marketing conferences, like SMX and BrightonSEO, and is a contributor to industry publications such as Search Engine Journal and State of Digital.
Frequently Asked Questions about webcrawler search engine
Is WebCrawler still around?
WebCrawler (1994; reborn 2001): WebCrawler still exists as a meta search engine that gets results from other search engines, rather than through its own efforts. Now owned by Infospace, WebCrawler was arguably the web’s first crawler-based search engine in the way we know them today.Mar 4, 2003
Is WebCrawler com safe?
Remember that webcrawler.com is legitimate, but visiting this site through other rogue sites is not recommended – if you want to use webcrawler.com as your web search engine, assign this URL directly, rather than using another website as a “gate”.Jul 31, 2018
What is crawling in search engine?
Crawling is the process used by search engine web crawlers (bots or spiders) to visit and download a page and extract its links in order to discover additional pages. … If a search engine detects changes to a page after crawling a page, it will update it’s index in response to these detected changes.