List Of Web Crawlers
Web Crawlers and User Agents – Top 10 Most Popular
By Brian JacksonUpdated on June 6, 2017
When it comes to the world wide web there are both bad bots and good bots. The bad bots you definitely want to avoid as these consume your CDN bandwidth, take up server resources, and steal your content. Good bots (also known as web crawlers) on the other hand, should be handled with care as they are a vital part of getting your content to index with search engines such as Google, Bing, and Yahoo. Read more below about some of the top 10 web crawlers and user agents to ensure you are handling them crawlersWeb crawlers, also known as web spiders or internet bots, are programs that browse the web in an automated manner for the purpose of indexing content. Crawlers can look at all sorts of data such as content, links on a page, broken links, sitemaps, and HTML code engines like Google, Bing, and Yahoo use crawlers to properly index downloaded pages so that users can find them faster and more efficiently when they are searching. Without web crawlers, there would be nothing to tell them that your website has new and fresh content. Sitemaps also can play a part in that process. So web crawlers, for the most part, are a good thing. However there are also issues sometimes when it comes to scheduling and load as a crawler might be constantly polling your site. And this is where a file comes into play. This file can help control the crawl traffic and ensure that it doesn’t overwhelm your crawlers identify themselves to a web server by using the User-Agent request header in an HTTP request, and each crawler has their own unique identifier. Most of the time you will need to examine your web server referrer logs to view web crawler placing a file at the root of your web server you can define rules for web crawlers, such as allow or disallow certain assets from being crawled. Web crawlers must follow the rules defined in this file. You can apply generic rules which apply to all bots or get more granular and specify their specific User-Agent string. Example 1This example instructs all Search engine robots to not index any of the website’s content. This is defined by disallowing the root / of your *
Disallow: /
Example 2This example achieves the opposite of the previous one. In this case, the instructions are still applied to all user agents, however there is nothing defined within the Disallow instruction, meaning that everything can be *
Disallow:
To see more examples make sure to check out our in-depth post on how to use a 10 web crawlers and botsThere are hundreds of web crawlers and bots scouring the internet but below is a list of 10 popular web crawlers and bots that we have been collected based on ones that we see on a regular basis within our web server logs. 1. GoogleBotGooglebot is obviously one of the most popular web crawlers on the internet today as it is used to index content for Google’s search engine. Patrick Sexton wrote a great article about what a Googlebot is and how it pertains to your website indexing. One great thing about Google’s web crawler is that they give us a lot of tools and control over the
Full User-Agent stringMozilla/5. 0 (compatible; Googlebot/2. 1; +)
Googlebot example in robots. txtThis example displays a little more granularity pertaining to the instructions defined. Here, the instructions are only relevant to Googlebot. More specifically, it is telling Google not to index a specific page (/no-index/) Googlebot
Disallow: /no-index/
Besides Google’s web search crawler, they actually have 9 additional web crawlers:Web crawlerUser-Agent stringGooglebot NewsGooglebot-NewsGooglebot ImagesGooglebot-Image/1. 0Googlebot VideoGooglebot-Video/1. 0Google Mobile (featured phone)SAMSUNG-SGH-E250/1. 0 Profile/MIDP-2. 0 Configuration/CLDC-1. 1 owser/6. 2. 3. c. 101 (GUI) MMP/2. 0 (compatible; Googlebot-Mobile/2. 1; +)Google SmartphoneMozilla/5. 0 (Linux; Android 6. 0. 1; Nexus 5X Build/MMB29P) AppleWebKit/537. 36 (KHTML, like Gecko) Chrome/41. 2272. 96 Mobile Safari/537. 36 (compatible; Googlebot/2. 1; +)Google Mobile Adsense(compatible; Mediapartners-Google/2. 1; +)Google AdsenseMediapartners-GoogleGoogle AdsBot (PPC landing page quality)AdsBot-Google (+)Google app crawler (fetch resources for mobile)AdsBot-Google-Mobile-AppsYou can use the Fetch tool in Google Search Console to test how Google crawls or renders a URL on your site. See whether Googlebot can access a page on your site, how it renders the page, and whether any page resources (such as images or scripts) are blocked to can also see the Googlebot crawl stats per day, the amount of kilobytes downloaded, and time spent downloading a Googlebot documentation. BingbotBingbot is a web crawler deployed by Microsoft in 2010 to supply information to their Bing search engine. This is the replacement of what used to be the MSN
Full User-Agent stringMozilla/5. 0 (compatible; Bingbot/2. 0; +)
Bing also has a very similar tool as Google, called Fetch as Bingbot, within Bing Webmaster Tools. Fetch As Bingbot allows you to request a page be crawled and shown to you as our crawler would see it. You will see the page code as Bingbot would see it, helping you to understand if they are seeing your page as you Bingbot documentation. Slurp BotYahoo Search results come from the Yahoo web crawler Slurp and Bing’s web crawler, as a lot of Yahoo is now powered by Bing. Sites should allow Yahoo Slurp access in order to appear in Yahoo Mobile Search ditionally, Slurp does the following:Collects content from partner sites for inclusion within sites like Yahoo News, Yahoo Finance and Yahoo cesses pages from sites across the Web to confirm accuracy and improve Yahoo’s personalized content for our
Full User-Agent stringMozilla/5. 0 (compatible; Yahoo! Slurp;)
See Slurp documentation. 4. DuckDuckBotDuckDuckBot is the Web crawler for DuckDuckGo, a search engine that has become quite popular lately as it is known for privacy and not tracking you. It now handles over 12 million queries per day. DuckDuckGo gets its results from over four hundred sources. These include hundreds of vertical sources delivering niche Instant Answers, DuckDuckBot (their crawler) and crowd-sourced sites (Wikipedia). They also have more traditional links in the search results, which they source from Yahoo!, Yandex and
Full User-Agent stringDuckDuckBot/1. 0; (+)
It respects WWW::RobotRules and originates from these IP addresses:72. 94. 249. 3472. 3572. 3672. 3772. 385. BaiduspiderBaiduspider is the official name of the Chinese Baidu search engine’s web crawling spider. It crawls web pages and returns updates to the Baidu index. Baidu is the leading Chinese search engine that takes an 80% share of the overall search engine market of China
Full User-Agent stringMozilla/5. 0 (compatible; Baiduspider/2. 0; +)
Besides Baidu’s web search crawler, they actually have 6 additional web crawlers:Web crawlerUser-Agent stringImage SearchBaiduspider-imageVideo SearchBaiduspider-videoNews SearchBaiduspider-newsBaidu wishlistsBaiduspider-favoBaidu UnionBaiduspider-cproBusiness SearchBaiduspider-adsOther search pagesBaiduspiderSee Baidu documentation. 6. Yandex BotYandexBot is the web crawler to one of the largest Russian search engines, Yandex. According to LiveInternet, for the three months ended December 31, 2015, they generated 57. 3% of all search traffic in
Full User-Agent stringMozilla/5. 0 (compatible; YandexBot/3. 0; +)
There are many different User-Agent strings that the YandexBot can show up as in your server logs. See the full list of Yandex robots and Yandex documentation. 7. Sogou SpiderSogou Spider is the web crawler for, a leading Chinese search engine that was launched in 2004. As of April 2016 it has a rank of 103 in Alexa’s internet The Sogou web spider does not respect the robots exclusion standard, and is therefore banned from many websites because of excessive Pic Spider/3. 0()
Sogou head spider/3. 0()
Sogou web spider/4. 0(+)
Sogou Orion spider/3. 0()
Sogou-Test-Spider/4. 0 (compatible; MSIE 5. 5; Windows 98)
8. ExabotExabot is a web crawler for Exalead, which is a search engine based out of France. It was founded in 2000 and now has more than 16 billion pages currently (compatible; Konqueror/3. 5; Linux) KHTML/3. 5. 5 (like Gecko) (Exabot-Thumbnails)
Mozilla/5. 0 (compatible; Exabot/3. 0; +)
See Exabot documentation. 9. Facebook external hitFacebook allows its users to send links to interesting web content to other Facebook users. Part of how this works on the Facebook system involves the temporary display of certain images or details related to the web content, such as the title of the webpage or the embed tag of a video. The Facebook system retrieves this information only after a user provides a of their main crawling bots is Facebot, which is designed to help improve advertising
facebookexternalhit/1. 0 (+)
facebookexternalhit/1. 1 (+)
See Facebot documentation. 10. Alexa crawleria_archiver is the web crawler for Amazon’s Alexa internet rankings. As you probably know they collect information to show rankings for both local and international
Full User-Agent stringia_archiver (+;)
See Ia_archiver botsAs we mentioned above most of those are actually good web crawlers. You generally don’t want to block Google or Bing from indexing your site unless you have a good reason. But what about the thousands of bad bots? KeyCDN released a new feature back in February 2016 that you can enable in your dashboard called Block Bad Bots. KeyCDN uses a comprehensive list of known bad bots and blocks them based on their User-Agent a new Zone is added the Block Bad Bots feature is set to disabled. This setting can be set to enabled instead if you want bad bots to automatically be resourcesPerhaps you are seeing some user-agent strings in your logs that have you concerned. Here are a couple of good resources in which you can lookup popular bad bots, crawlers, and Caio Almeida also has a pretty good list on his crawler-user-agents GitHub mmaryThere are hundreds of different web crawlers out there but hopefully you are now familiar with couple of the more popular ones. Again you want to be careful when blocking any of these as they could cause indexing issues. It is always good to check your web server logs to see how often they are actually crawling your we miss any important ones? If so please let us know below and we will add them.

Top 20 web crawler tools to scrape the websites – Big Data …
Web crawling (also known as web scraping) is a process in which a program or automated script browses the World Wide Web in a methodical, automated manner and targets at fetching new or updated data from any websites and store the data for easy access. Web crawler tools are very popular these days as they have simplified and automated the entire crawling process and made the data crawling easy and accessible to everyone. In this post, we will look at the top 20 popular web crawlers around the web. 1. Cyotek WebCopyWebCopy is a free website crawler that allows you to copy partial or full websites locally into your hard disk for offline will scan the specified website before downloading the website content onto your hard disk and auto-remap the links to resources like images and other web pages in the site to match its local path, excluding a section of the website. Additional options are also available such as downloading a URL to include in the copy, but not crawling are many settings you can make to configure how your website will be crawled, in addition to rules and forms mentioned above, you can also configure domain aliases, user agent strings, default documents and ever, WebCopy does not include a virtual DOM or any form of JavaScript parsing. If a website makes heavy use of JavaScript to operate, it is unlikely WebCopy will be able to make a true copy if it is unable to discover all the website due to JavaScript being used to dynamically generate links. 2. HTTrackAs a website crawler freeware, HTTrack provides functions well suited for downloading an entire website from the Internet to your PC. It has provided versions available for Windows, Linux, Sun Solaris, and other Unix systems. It can mirror one site, or more than one site together (with shared links). You can decide the number of connections to opened concurrently while downloading web pages under “Set options”. You can get the photos, files, HTML code from the entire directories, update current mirrored website and resume interrupted, Proxy support is available with HTTTrack to maximize speed, with optional Track Works as a command-line program, or through a shell for both private (capture) or professional (on-line web mirror) use. With that saying, HTTrack should be preferred and used more by people with advanced programming skills. 3. OctoparseOctoparse is a free and powerful website crawler used for extracting almost all kind of data you need from the website. You can use Octoparse to rip a website with its extensive functionalities and capabilities. There are two kinds of learning mode – Wizard Mode and Advanced Mode – for non-programmers to quickly get used to Octoparse. After downloading the freeware, its point-and-click UI allows you to grab all the text from the website and thus you can download almost all the website content and save it as a structured format like EXCEL, TXT, HTML or your advanced, it has provided Scheduled Cloud Extraction which enables you to refresh the website and get the latest information from the you could extract many tough websites with difficult data block layout using its built-in Regex tool, and locate web elements precisely using the XPath configuration tool. You will not be bothered by IP blocking anymore since Octoparse offers IP Proxy Servers that will automate IP’s leaving without being detected by aggressive conclude, Octoparse should be able to satisfy users’ most crawling needs, both basic or high-end, without any coding skills. 4. GetleftGetleft is a free and easy-to-use website grabber that can be used to rip a website. It downloads an entire website with its easy-to-use interface and multiple options. After you launch the Getleft, you can enter a URL and choose the files that should be downloaded before begin downloading the website. While it goes, it changes the original pages, all the links get changed to relative links, for local browsing. Additionally, it offers multilingual support, at present Getleft supports 14 languages. However, it only provides limited Ftp supports, it will download the files but not recursively. Overall, Getleft should satisfy users’ basic crawling needs without more complex tactical skills. 5. ScraperThe scraper is a Chrome extension with limited data extraction features but it’s helpful for making online research, and exporting data to Google Spreadsheets. This tool is intended for beginners as well as experts who can easily copy data to the clipboard or store to the spreadsheets using OAuth. The scraper is a free web crawler tool, which works right in your browser and auto-generates smaller XPaths for defining URLs to crawl. It may not offer all-inclusive crawling services, but novices also needn’t tackle messy configurations. 6. OutWit HubOutWit Hub is a Firefox add-on with dozens of data extraction features to simplify your web searches. This web crawler tool can browse through pages and store the extracted information in a proper Hub offers a single interface for scraping tiny or huge amounts of data per needs. OutWit Hub lets you scrape any web page from the browser itself and even create automatic agents to extract data and format it per is one of the simplest web scraping tools, which is free to use and offers you the convenience to extract web data without writing a single line of code. 7. ParseHubParsehub is a great web crawler that supports collecting data from websites that use AJAX technologies, JavaScript, cookies etc. Its machine learning technology can read, analyze and then transform web documents into relevant desktop application of Parsehub supports systems such as Windows, Mac OS X and Linux, or you can use the web app that is built within the a freeware, you can set up no more than five public projects in Parsehub. The paid subscription plans allow you to create at least 20 private projects for scraping websites. 8. Visual ScraperVisualScraper is another great free and non-coding web scraper with a simple point-and-click interface and could be used to collect data from the web. You can get real-time data from several web pages and export the extracted data as CSV, XML, JSON or SQL files. Besides the SaaS, VisualScraper offers web scraping service such as data delivery services and creating software extractors Scraper enables users to schedule their projects to be run on a specific time or repeat the sequence every minute, days, week, month, year. Users could use it to extract news, updates, forum frequently. 9. ScrapinghubScrapinghub is a cloud-based data extraction tool that helps thousands of developers to fetch valuable data. Its open source visual scraping tool, allows users to scrape websites without any programming rapinghub uses Crawlera, a smart proxy rotator that supports bypassing bot counter-measures to crawl huge or bot-protected sites easily. It enables users to crawl from multiple IPs and locations without the pain of proxy management through a simple HTTP rapinghub converts the entire web page into organized content. Its team of experts is available for help in case its crawl builder can’t work your requirements. 10. a browser-based web crawler, allows you to scrape data based on your browser from any website and provide three types of the robot for you to create a scraping task – Extractor, Crawler, and Pipes. The freeware provides anonymous web proxy servers for your web scraping and your extracted data will be hosted on ’s servers for two weeks before the data is archived, or you can directly export the extracted data to JSON or CSV files. It offers paid services to meet your needs for getting real-time data. 11. enables users to get real-time data from crawling online sources from all over the world into various, clean formats. This web crawler enables you to crawl data and further extract keywords in many different languages using multiple filters covering a wide array of you can save the scraped data in XML, JSON and RSS formats. And users can access the history data from its Archive. Plus, supports at most 80 languages with its crawling data results. And users can easily index and search the structured data crawled by, could satisfy users’ elementary crawling requirements. 12. Import. ioUsers can form their own datasets by simply importing the data from a web page and exporting the data to can easily scrape thousands of web pages in minutes without writing a single line of code and build 1000+ APIs based on your requirements. Public APIs has provided powerful and flexible capabilities to control programmatically and gain automated access to the data, has made crawling easier by integrating web data into your own app or website with just a few better serve users’ crawling requirements, it also offers a free app for Windows, Mac OS X and Linux to build data extractors and crawlers, download data and sync with the online account. Plus, users can schedule crawling tasks weekly, daily or hourly. 13. 80legs80legs is a powerful web crawling tool that can be configured based on customized requirements. It supports fetching huge amounts of data along with the option to download the extracted data instantly. 80legs provides high-performance web crawling that works rapidly and fetches required data in mere seconds14. Spinn3rSpinn3r allows you to fetch entire data from blogs, news & social media sites and RSS & ATOM feed. Spinn3r is distributed with a firehouse API that manages 95% of the indexing work. It offers advanced spam protection, which removes spam and inappropriate language uses, thus improving data safety. Spinn3r indexes content like Google and save the extracted data in JSON files. The web scraper constantly scans the web and finds updates from multiple sources to get you real-time publications. Its admin console lets you control crawls and full-text search allows making complex queries on raw data. 15. Content GrabberContent Graber is a web crawling software targeted at enterprises. It allows you to create a stand-alone web crawling agents. It can extract content from almost any website and save it as structured data in a format of your choice, including Excel reports, XML, CSV, and most is more suitable for people with advanced programming skills, since it offers many powerful scripting editing, debugging interfaces for people in need. Users can use C# or to debug or write the script to control the crawling programming. For example, Content Grabber can integrate with Visual Studio 2013 for the most powerful script editing, debugging and unit test for an advanced and tactful customized crawler based on users’ particular needs. 16. Helium ScraperHelium Scraper is a visual web data crawling software that works well when the association between elements is small. It’s non-coding, non-configuration. And users can get access to the online templates based for various crawling needs. Basically, it could satisfy users’ crawling needs within an elementary level. 17. UiPathUiPath is a robotic process automation software for free web scraping. It automates web and desktop data crawling out of most third-party Apps. You can install the robotic process automation software if you run a Windows system. Uipath can extract tabular and pattern-based data across multiple web has provided the built-in tools for further crawling. This method is very effective when dealing with complex UIs. The Screen Scraping Tool can handle both individual text elements, groups of text and blocks of text, such as data extraction in table, no programming is needed to create intelligent web agents, but the hacker inside you will have complete control over the data. 18. Scrape. is a web scraping software for humans. It’s a cloud-based web data extraction tool. It’s designed towards those with advanced programming skills, since it has offered both public and private packages to discover, reuse, update, and share code with millions of developers worldwide. Its powerful integration will help you build a customized crawler based on your needs. 19. WebHarvyWebHarvy is a point-and-click web scraping software. It’s designed for non-programmers. WebHarvy can automatically scrape Text, Images, URLs & Emails from websites, and save the scraped content in various formats. It also provides built-in scheduler and proxy support which enables anonymously crawling and prevents the web scraping software from being blocked by web servers, you have the option to access target websites via proxy servers or can save the data extracted from web pages in a variety of formats. The current version of WebHarvy Web Scraper allows you to export the scraped data as an XML, CSV, JSON or TSV file. The user can also export the scraped data to an SQL database. 20. ConnotateConnotate is an automated web crawler designed for Enterprise-scale web content extraction which needs an enterprise-scale solution. Business users can easily create extraction agents in as little as minutes – without any programming. The user can easily create extraction agents simply by can automatically extract over 95% of sites without programming, including complex JavaScript-based dynamic site technologies, such as Ajax. And Connotate supports any language for data crawling from most ditionally, Connotate also offers the function to integrate webpage and database content, including content from SQL databases and MongoDB for database added to the list:21. Netpeak SpiderNetpeak Spider is a desktop tool for day-to-day SEO audit, quick search for issues, systematic analysis, and website program specializes in the analysis of large websites (we’re talking about millions of pages) with optimal use of RAM. You can simply import the data from web crawling and export the data to tpeak Spider allows you to scrape custom search of source code/text according to the 4 types of search: ‘Contains’, ‘RegExp’, ‘CSS Selector’, or ‘XPath’. A tool is useful for scraping for emails, names, etc.

What is a web crawler? | How web spiders work | Cloudflare
What is a web crawler bot?
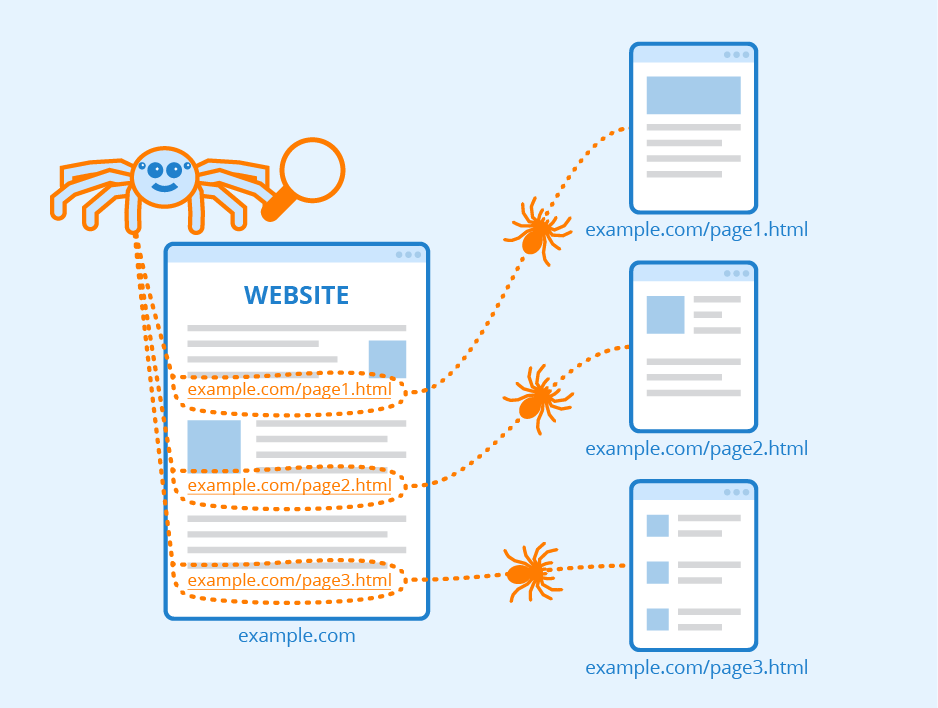
A web crawler, spider, or search engine bot downloads and indexes content from all over the Internet. The goal of such a bot is to learn what (almost) every webpage on the web is about, so that the information can be retrieved when it’s needed. They’re called “web crawlers” because crawling is the technical term for automatically accessing a website and obtaining data via a software program.
These bots are almost always operated by search engines. By applying a search algorithm to the data collected by web crawlers, search engines can provide relevant links in response to user search queries, generating the list of webpages that show up after a user types a search into Google or Bing (or another search engine).
A web crawler bot is like someone who goes through all the books in a disorganized library and puts together a card catalog so that anyone who visits the library can quickly and easily find the information they need. To help categorize and sort the library’s books by topic, the organizer will read the title, summary, and some of the internal text of each book to figure out what it’s about.
However, unlike a library, the Internet is not composed of physical piles of books, and that makes it hard to tell if all the necessary information has been indexed properly, or if vast quantities of it are being overlooked. To try to find all the relevant information the Internet has to offer, a web crawler bot will start with a certain set of known webpages and then follow hyperlinks from those pages to other pages, follow hyperlinks from those other pages to additional pages, and so on.
It is unknown how much of the publicly available Internet is actually crawled by search engine bots. Some sources estimate that only 40-70% of the Internet is indexed for search – and that’s billions of webpages.
What is search indexing?
Search indexing is like creating a library card catalog for the Internet so that a search engine knows where on the Internet to retrieve information when a person searches for it. It can also be compared to the index in the back of a book, which lists all the places in the book where a certain topic or phrase is mentioned.
Indexing focuses mostly on the text that appears on the page, and on the metadata* about the page that users don’t see. When most search engines index a page, they add all the words on the page to the index – except for words like “a, ” “an, ” and “the” in Google’s case. When users search for those words, the search engine goes through its index of all the pages where those words appear and selects the most relevant ones.
*In the context of search indexing, metadata is data that tells search engines what a webpage is about. Often the meta title and meta description are what will appear on search engine results pages, as opposed to content from the webpage that’s visible to users.
How do web crawlers work?
The Internet is constantly changing and expanding. Because it is not possible to know how many total webpages there are on the Internet, web crawler bots start from a seed, or a list of known URLs. They crawl the webpages at those URLs first. As they crawl those webpages, they will find hyperlinks to other URLs, and they add those to the list of pages to crawl next.
Given the vast number of webpages on the Internet that could be indexed for search, this process could go on almost indefinitely. However, a web crawler will follow certain policies that make it more selective about which pages to crawl, in what order to crawl them, and how often they should crawl them again to check for content updates.
The relative importance of each webpage: Most web crawlers don’t crawl the entire publicly available Internet and aren’t intended to; instead they decide which pages to crawl first based on the number of other pages that link to that page, the amount of visitors that page gets, and other factors that signify the page’s likelihood of containing important information.
The idea is that a webpage that is cited by a lot of other webpages and gets a lot of visitors is likely to contain high-quality, authoritative information, so it’s especially important that a search engine has it indexed – just as a library might make sure to keep plenty of copies of a book that gets checked out by lots of people.
Revisiting webpages: Content on the Web is continually being updated, removed, or moved to new locations. Web crawlers will periodically need to revisit pages to make sure the latest version of the content is indexed.
requirements: Web crawlers also decide which pages to crawl based on the protocol (also known as the robots exclusion protocol). Before crawling a webpage, they will check the file hosted by that page’s web server. A file is a text file that specifies the rules for any bots accessing the hosted website or application. These rules define which pages the bots can crawl, and which links they can follow. As an example, check out the file.
All these factors are weighted differently within the proprietary algorithms that each search engine builds into their spider bots. Web crawlers from different search engines will behave slightly differently, although the end goal is the same: to download and index content from webpages.
Why are web crawlers called ‘spiders’?
The Internet, or at least the part that most users access, is also known as the World Wide Web – in fact that’s where the “www” part of most website URLs comes from. It was only natural to call search engine bots “spiders, ” because they crawl all over the Web, just as real spiders crawl on spiderwebs.
Should web crawler bots always be allowed to access web properties?
That’s up to the web property, and it depends on a number of factors. Web crawlers require server resources in order to index content – they make requests that the server needs to respond to, just like a user visiting a website or other bots accessing a website. Depending on the amount of content on each page or the number of pages on the site, it could be in the website operator’s best interests not to allow search indexing too often, since too much indexing could overtax the server, drive up bandwidth costs, or both.
Also, developers or companies may not want some webpages to be discoverable unless a user already has been given a link to the page (without putting the page behind a paywall or a login). One example of such a case for enterprises is when they create a dedicated landing page for a marketing campaign, but they don’t want anyone not targeted by the campaign to access the page. In this way they can tailor the messaging or precisely measure the page’s performance. In such cases the enterprise can add a “no index” tag to the landing page, and it won’t show up in search engine results. They can also add a “disallow” tag in the page or in the file, and search engine spiders won’t crawl it at all.
Website owners may not want web crawler bots to crawl part or all of their sites for a variety of other reasons as well. For instance, a website that offers users the ability to search within the site may want to block the search results pages, as these are not useful for most users. Other auto-generated pages that are only helpful for one user or a few specific users should also be blocked.
What is the difference between web crawling and web scraping?
Web scraping, data scraping, or content scraping is when a bot downloads the content on a website without permission, often with the intention of using that content for a malicious purpose.
Web scraping is usually much more targeted than web crawling. Web scrapers may be after specific pages or specific websites only, while web crawlers will keep following links and crawling pages continuously.
Also, web scraper bots may disregard the strain they put on web servers, while web crawlers, especially those from major search engines, will obey the file and limit their requests so as not to overtax the web server.
How do web crawlers affect SEO?
SEO stands for search engine optimization, and it is the discipline of readying content for search indexing so that a website shows up higher in search engine results.
If spider bots don’t crawl a website, then it can’t be indexed, and it won’t show up in search results. For this reason, if a website owner wants to get organic traffic from search results, it is very important that they don’t block web crawler bots.
What web crawler bots are active on the Internet?
The bots from the major search engines are called:
Google: Googlebot (actually two crawlers, Googlebot Desktop and Googlebot Mobile, for desktop and mobile searches)
Bing: Bingbot
Yandex (Russian search engine): Yandex Bot
Baidu (Chinese search engine): Baidu Spider
There are also many less common web crawler bots, some of which aren’t associated with any search engine.
Why is it important for bot management to take web crawling into account?
Bad bots can cause a lot of damage, from poor user experiences to server crashes to data theft. However, in blocking bad bots, it’s important to still allow good bots, such as web crawlers, to access web properties. Cloudflare Bot Management allows good bots to keep accessing websites while still mitigating malicious bot traffic. The product maintains an automatically updated allowlist of good bots, like web crawlers, to ensure they aren’t blocked. Smaller organizations can gain a similar level of visibility and control over their bot traffic with Super Bot Fight Mode, available on Cloudflare Pro and Business plans.
Frequently Asked Questions about list of web crawlers
Which web crawler is best?
Top 20 web crawler tools to scrape the websitesCyotek WebCopy. WebCopy is a free website crawler that allows you to copy partial or full websites locally into your hard disk for offline reading. … HTTrack. … Octoparse. … Getleft. … Scraper. … OutWit Hub. … ParseHub. … Visual Scraper.More items…•Jun 3, 2017
What are crawlers on websites?
A web crawler, or spider, is a type of bot that is typically operated by search engines like Google and Bing. Their purpose is to index the content of websites all across the Internet so that those websites can appear in search engine results.
What are different types of crawlers?
2 Types of Web Crawler2.1 Focused Web Crawler. Focused web crawler selectively search for web pages relevant to specific user fields or topics. … 2.2 Incremental Web Crawler. … 2.3 Distributed Web Crawler. … 2.4 Parallel Web Crawler. … 2.5 Hidden Web Crawler.Aug 28, 2019