Javascript Screen Scrape
Web Scraping Using Node JS in JavaScript – Analytics Vidhya
This article was published as a part of the Data Science Blogathon.
to f
INTRODUCTION
Gathering information across the web is web scraping, also known as Web Data Extraction & Web Harvesting. Nowadays data is like oxygen for startups & freelancers who want to start a business or a project in any domain. Suppose you want to find the price of a product on an eCommerce website. It’s easy to find but now let’s say you have to do this exercise for thousands of products across multiple eCommerce websites. Doing it manually; not a good option at all.
Get to know the Tool
JavaScript is a popular programming language and it runs in any web browser.
Node JS is an interpreter and provides an environment for JavaScript with some specific useful libraries.
In short, Node JS adds several functionality & features to JavaScript in terms of libraries & make it more powerful.
Hands-On-Session
Let’s get to understand web scraping using Node JS with an example. Suppose you want to analyze the price fluctuations of some products on an eCommerce website. Now, you have to list out all the possible factors of the cause & cross-check it with each product. Similarly, when you want to scrape data, then you have to list out parent HTML tags & check respective child HTML tag to extract the data by repeating this activity.
Steps Required for Web Scraping
Creating the file
Install & Call the required libraries
Select the Website & Data needed to Scrape
Set the URL & Check the Response Code
Inspect & Find the Proper HTML tags
Include the HTML tags in our Code
Cross-check the Scraped Data
I’m using Visual Studio to run this task.
Step 1- Creating the file
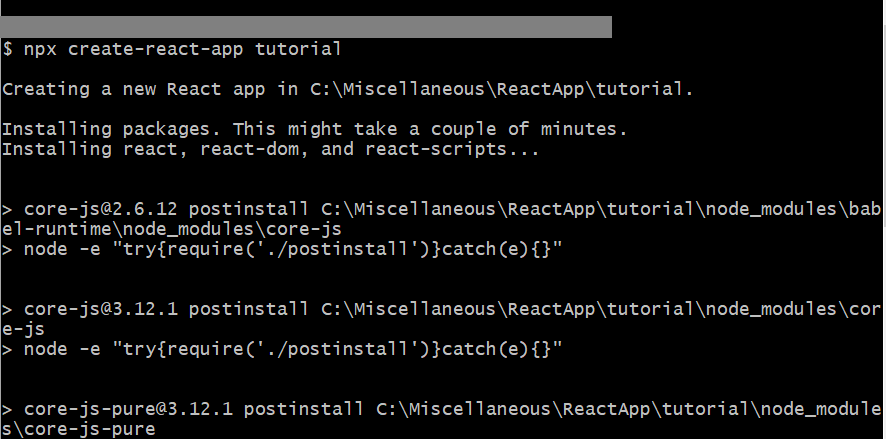
To create a file, I need to run npm init and give a few details as needed in the below screenshot.
Create
Step 2- Install & Call the required libraries
Need to run the below codes to install these libraries.
Install Libraries
Once the libraries are properly installed then you will see these messages are getting displayed.
logs after packages get installed
Call the required libraries:
Call the library
Step 3- Select the Website & Data needed to Scrape.
I picked this website “ and want to scrape data of gold rates along with dates.
Data we want to scrape
Step 4- Set the URL & Check the Response Code
Node JS code looks like this to pass the URL & check the response code.
Passing URL & Getting Response Code
Step 5- Inspect & Find the Proper HTML tags
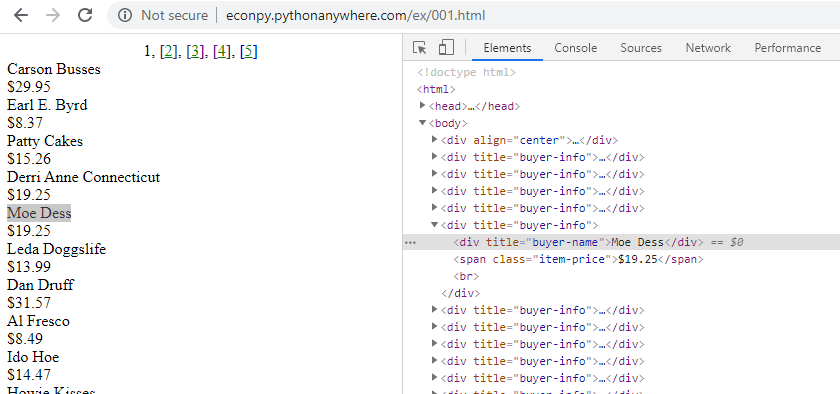
It’s quite easy to find the proper HTML tags in which your data is present.
To see the HTML tags; right-click and select the inspect option.
Inspecting the HTML Tags
Select proper HTML Tags:-
If you noticed there are three columns in our table, so our HTML tag for table row would be “HeaderRow” & all the column names are present with tag “th” (Table Header).
And for each table row (“tr”) our data resides in “DataRow” HTML tag
Now, I need to get all HTML tags to reside under “HeaderRow” & need to find all the “th” HTML tags & finally iterate through “DataRow” HTML tag to get all the data within it.
Step 6- Include the HTML tags in our Code
After including the HTML tags, our code will be:-
Code Snippet
Step 7- Cross-check the Scraped Data
Print the Data, so the code for this is like:-
Our Scraped Data
If you go to a more granular level of HTML Tags & iterate them accordingly, you will get more precise data.
That’s all about web scraping & how to get rare quality data like gold.
Conclusion
I tried to explain Web Scraping using Node JS in a precise way. Hopefully, this will help you.
Find full code on
Vgyaan’s–GithubRepo
If you have any questions about the code or web scraping in general, reach out to me on
Vgyaan’s–Linkedin
We will meet again with something new.
Till then,
Happy Coding..!

Web Scraping 101: 10 Myths that Everyone Should Know | Octoparse
1. Web Scraping is illegal
Many people have false impressions about web scraping. It is because there are people don’t respect the great work on the internet and use it by stealing the content. Web scraping isn’t illegal by itself, yet the problem comes when people use it without the site owner’s permission and disregard of the ToS (Terms of Service). According to the report, 2% of online revenues can be lost due to the misuse of content through web scraping. Even though web scraping doesn’t have a clear law and terms to address its application, it’s encompassed with legal regulations. For example:
Violation of the Computer Fraud and Abuse Act (CFAA)
Violation of the Digital Millennium Copyright Act (DMCA)
Trespass to Chattel
Misappropriation
Copy right infringement
Breach of contract
Photo by Amel Majanovic on Unsplash
2. Web scraping and web crawling are the same
Web scraping involves specific data extraction on a targeted webpage, for instance, extract data about sales leads, real estate listing and product pricing. In contrast, web crawling is what search engines do. It scans and indexes the whole website along with its internal links. “Crawler” navigates through the web pages without a specific goal.
3. You can scrape any website
It is often the case that people ask for scraping things like email addresses, Facebook posts, or LinkedIn information. According to an article titled “Is web crawling legal? ” it is important to note the rules before conduct web scraping:
Private data that requires username and passcodes can not be scrapped.
Compliance with the ToS (Terms of Service) which explicitly prohibits the action of web scraping.
Don’t copy data that is copyrighted.
One person can be prosecuted under several laws. For example, one scraped some confidential information and sold it to a third party disregarding the desist letter sent by the site owner. This person can be prosecuted under the law of Trespass to Chattel, Violation of the Digital Millennium Copyright Act (DMCA), Violation of the Computer Fraud and Abuse Act (CFAA) and Misappropriation.
It doesn’t mean that you can’t scrape social media channels like Twitter, Facebook, Instagram, and YouTube. They are friendly to scraping services that follow the provisions of the file. For Facebook, you need to get its written permission before conducting the behavior of automated data collection.
4. You need to know how to code
A web scraping tool (data extraction tool) is very useful regarding non-tech professionals like marketers, statisticians, financial consultant, bitcoin investors, researchers, journalists, etc. Octoparse launched a one of a kind feature – web scraping templates that are preformatted scrapers that cover over 14 categories on over 30 websites including Facebook, Twitter, Amazon, eBay, Instagram and more. All you have to do is to enter the keywords/URLs at the parameter without any complex task configuration. Web scraping with Python is time-consuming. On the other side, a web scraping template is efficient and convenient to capture the data you need.
5. You can use scraped data for anything
It is perfectly legal if you scrape data from websites for public consumption and use it for analysis. However, it is not legal if you scrape confidential information for profit. For example, scraping private contact information without permission, and sell them to a 3rd party for profit is illegal. Besides, repackaging scraped content as your own without citing the source is not ethical as well. You should follow the idea of no spamming, no plagiarism, or any fraudulent use of data is prohibited according to the law.
Check Below Video: 10 Myths About Web Scraping!
6. A web scraper is versatile
Maybe you’ve experienced particular websites that change their layouts or structure once in a while. Don’t get frustrated when you come across such websites that your scraper fails to read for the second time. There are many reasons. It isn’t necessarily triggered by identifying you as a suspicious bot. It also may be caused by different geo-locations or machine access. In these cases, it is normal for a web scraper to fail to parse the website before we set the adjustment.
Read this article: How to Scrape Websites Without Being Blocked in 5 Mins?
7. You can scrape at a fast speed
You may have seen scraper ads saying how speedy their crawlers are. It does sound good as they tell you they can collect data in seconds. However, you are the lawbreaker who will be prosecuted if damages are caused. It is because a scalable data request at a fast speed will overload a web server which might lead to a server crash. In this case, the person is responsible for the damage under the law of “trespass to chattels” law (Dryer and Stockton 2013). If you are not sure whether the website is scrapable or not, please ask the web scraping service provider. Octoparse is a responsible web scraping service provider who places clients’ satisfaction in the first place. It is crucial for Octoparse to help our clients get the problem solved and to be successful.
8. API and Web scraping are the same
API is like a channel to send your data request to a web server and get desired data. API will return the data in JSON format over the HTTP protocol. For example, Facebook API, Twitter API, and Instagram API. However, it doesn’t mean you can get any data you ask for. Web scraping can visualize the process as it allows you to interact with the websites. Octoparse has web scraping templates. It is even more convenient for non-tech professionals to extract data by filling out the parameters with keywords/URLs.
9. The scraped data only works for our business after being cleaned and analyzed
Many data integration platforms can help visualize and analyze the data. In comparison, it looks like data scraping doesn’t have a direct impact on business decision making. Web scraping indeed extracts raw data of the webpage that needs to be processed to gain insights like sentiment analysis. However, some raw data can be extremely valuable in the hands of gold miners.
With Octoparse Google Search web scraping template to search for an organic search result, you can extract information including the titles and meta descriptions about your competitors to determine your SEO strategies; For retail industries, web scraping can be used to monitor product pricing and distributions. For example, Amazon may crawl Flipkart and Walmart under the “Electronic” catalog to assess the performance of electronic items.
10. Web scraping can only be used in business
Web scraping is widely used in various fields besides lead generation, price monitoring, price tracking, market analysis for business. Students can also leverage a Google scholar web scraping template to conduct paper research. Realtors are able to conduct housing research and predict the housing market. You will be able to find Youtube influencers or Twitter evangelists to promote your brand or your own news aggregation that covers the only topics you want by scraping news media and RSS feeds.
Source:
Dryer, A. J., and Stockton, J. 2013. “Internet ‘Data Scraping’: A Primer for Counseling Clients, ” New York Law Journal. Retrieved from

Four problems with screen scraping that an API-First approach solves
screen scraper What is screen scraping? Screen scraping is what a developer might do to get access to information that’s usually only shared via a webpage. The idea of scraping the screen, meaning, programmatically taking what the user would normally see on the screen so that the developer can get access to the data outside of the “application” (web page/web app) in which it’s screen scraper uses code to access a webpage just the same way that a user would. The code pretends to be the user in a browser, intercepts the stream of bits, and instead of displaying them in a browser analyzes them to get at the desired information on the this is benign. A company that wants to consolidate points and status for a person across all the person’s airline mileage accounts could deliver a point tracking portal. A financial planning company might want access to all a customer’s accounts so that a full financial picture can be seen in one single fact, this conflict (between customers/scrapers and data-holders/owners) is one driver of Open Banking regulations (like XS2A APIs in PSD2) which try to answer the question of who the data belongs does this happen? It happens because the data is useful and not available happens because the companies that have the data only see THEIR OWN POINT OF VIEW, but not the COMPLETE CUSTOMER POINT OF VIEW. As in my definition of digital transformation, they only their own process, not their customer’s my examples above… I would have to go to every airline and hotel website to check my point balance, or I can look at my point dashboard. I may want to use multiple banks AND also want to see a complete picture of my financial situation in one problems with screen scrapingThe screen scraper is given the user’s authentication information (by the user) and stores it (hopefully securely) and uses it to access the information provider’s site. In plain English, I would give the company creating my financial picture all the login information for each bank and financial company I use. That is a risk to the financial institution because credentials for accounts they own are stored on someone else’s scrapers are “hitting the website” as if they were a logged-in user. However, they are not human, so they can hit the website much more frequently. And they hit it more frequently to stay up to date. Also, they download a lot more information than they need (they need the whole page, including HTML/CSS, and everything present on the page, even if they just want a line item) because that’s all they have access to–ages of data (instead of specific data fields) and money. Companies, especially banks, fight screen scraping with time and people (and technology). One wishes they would simply spend that time and money to create a great API. Though often, they cannot figure out the business customer experience. I’m sure there’s more but I can quickly think of three issues that impact customer experience:There are errors because it is a hack. If the website changes even a little, the data may not be found until the screen scraper adapts. It’s a constant battle where the customer ’s slow because of #2 above. A lot of data must be downloaded and processed just to get at a few necessary bits. To stay up to date in case there are changes that data must be downloaded stops working because it’s an us-vs-them situation, and the companies are working to prevent this from happening. When those companies are successful, it stops working for the definitely creates an “us vs. them” (it’s my data, but I can’t get it… vs the company who holds the data) when many companies are trying to “be in this together” or deliver a “great experience. ”Even though it’s hardest to measure, the customer experience thing might be the most critical driver to move from an us-vs-them attitude towards an Open API Platform one, even if there are open questions as to measuring the business justification:Customer experience will overtake price as the key brand differentiator (2020, Walker). 65% of consumers think that positive experience with a brand is more influential than great advertising (2018; PWC) of organizations consider delivering easy, fun and valuable experiences a key competitive advantage in the financial services industry (2019, Adobe). I have seen examples where banks create apps (like for FX or treasury management) but do not provide access to the raw data through an API. The customer asks for access to the data, but the bank cannot figure out the ROI for doing so and does nothing. As such, there’s tension until the customer threatens to leave the bank and the bank begrudgingly ’s not the kind of provider I want to do business with… a begrudging one. Don’t be that partner. Be the one that has a “better together” should companies do instead? Create an API with proper authentication to resolve security and customer experience concerns and lower the burden on their web infrastructure (points #1 & 2 above). By partnering with customers to give them access to the data, they can figure out new business models and build better collaborative relationships to identify new needs and net-new benefits of creating an API platform include:Creating a managed ecosystem to capture value from FinTech and partners. Plaid is just an obvious example, but most innovators would rather not reinvent. Creating something of value, expose it as an API and others will build on top of your offering rather than solutions that are more valuable for customers because they integrate at a deeper technical level; these solutions are also “stickier” with customers because once the integration is complete it often becomes a base-layer on which other value is built. Enabling automation. We see a lot of companies talking about digitizing processes and automating repetitive tasks to increase efficiency. That’s just “fancy talk” for APIs. The key thing is that with a platform you empower those less technical to create orchestrations to solve their own efficiency aspirations. This last bit is important because Axway research has identified that 86% of IT leaders believe that IT should be spending more time enabling others to integrate for course, there are technical answers about what should be done. However, more important is understanding the fundamental cultural changes and the required business transformation that drives this new way of thinking about customers, experience and creating compelling has built a team of industry leaders that we’ve called Catalysts to help catalyze exactly this sort of change. The Catalysts work with customers in a variety of workshop formats from executive to implementors to help drive change and embrace the cause after all, it’s not really about your APIs or your API Platform, but about your people and enabling them to connect to customers around the value that you’re creating for my last post “3 Reasons to Create an API Platform for your API Practice. ”
Frequently Asked Questions about javascript screen scrape
Can you web scrape with Javascript?
js, JavaScript is a great language to use for a web scraper: not only is Node fast, but you’ll likely end up using a lot of the same methods you’re used to from querying the DOM with front-end JavaScript.
How do you screen scrape in Javascript?
Steps Required for Web ScrapingCreating the package.json file.Install & Call the required libraries.Select the Website & Data needed to Scrape.Set the URL & Check the Response Code.Inspect & Find the Proper HTML tags.Include the HTML tags in our Code.Cross-check the Scraped Data.Oct 27, 2020
Is it legal to scrape API?
It is perfectly legal if you scrape data from websites for public consumption and use it for analysis. However, it is not legal if you scrape confidential information for profit. For example, scraping private contact information without permission, and sell them to a 3rd party for profit is illegal.Aug 16, 2021